Tadalafil zeigt eine konstante Resorption im Gastrointestinaltrakt, mit maximalen Plasmaspiegeln nach rund zwei Stunden. Der Wirkstoff verteilt sich gut im Gewebe und weist eine hohe Plasmaproteinbindung auf. Seine lange Halbwertszeit erlaubt eine verlängerte Wirkphase. Der Metabolismus erfolgt über das hepatische Enzymsystem CYP3A4, mit der Bildung inaktiver Metaboliten. Exkretion geschieht primär über den Stuhl. Die Häufigkeit von Nebenwirkungen steigt mit der Dosis, wobei vor allem vasodilatatorische Effekte dominieren. Ein gängiger Bezugspunkt in pharmakologischen Analysen ist cialis ohne rezept, das mit dieser Wirkstoffklasse assoziiert ist.
Nil.fdi.ucm.es
Improving Summarization of Biomedical Documents
† Universidad Complutense de Madrid, C/Prof. Jos´e Garc´ıa Santesmases, 28040 Madrid, Spain
∗ University of Sheffield, Regent Court, 211 Portobello St., Sheffield, S1 4DP, UK
al., 2004). These approaches can represent seman-tic associations between the words and terms in the
document (i.e. synonymy, hypernymy, homonymy
or co-occurrence) and use this information to im-
show that its performance can be improved
prove the quality of the summaries. In the biomed-
ical domain the Unified Medical Language Sys-
system represents the documents as graphs
tem (UMLS) (Nelson et al., 2002) has proved to
be a useful knowledge source for summarization
(Fiszman et al., 2004; Reeve et al., 2007; Plaza et
gorithm is applied to these graphs to dis-
al., 2008). In order to access the information con-
tained in the UMLS, the vocabulary of the doc-
ument being summarized has to be mapped onto
it. However, ambiguity is common in biomedi-
cal documents (Weeber et al., 2001). For exam-
ple, the string “cold” is associated with seven pos-
sible meanings in the UMLS Metathesuarus in-
cluding “common cold”, “cold sensation” , “cold
temperature” and “Chronic Obstructive Airway
tems in the biomedical domain rely on MetaMap
(Aronson, 2001) to map the text onto concepts
Extractive text summarization can be defined as
from the UMLS Metathesaurus (Fiszman et al.,
the process of determining salient sentences in a
2004; Reeve et al., 2007). However, MetaMap fre-
text. These sentences are expected to condense
quently fails to identify a unique mapping and, as
the relevant information regarding the main topic
a result, various concepts with the same score are
covered in the text. Automatic summarization of
returned. For instance, for the phrase “tissues are
biomedical texts may benefit both health-care ser-
often cold” MetaMap returns three equally scored
vices and biomedical research (Reeve et al., 2007;
concepts for the word ‘‘cold”: “common cold”,
Hunter and Cohen, 2006). Providing physicians
“cold sensation” and ”cold temperature”.
with summaries of their patient records can help
The purpose of this paper is to study the ef-
to reduce the diagnosis time. Researchers can use
fect of lexical ambiguity in the knowledge source
summaries to quickly determine whether a docu-
on semantic approaches to biomedical summariza-
ment is of interest without having to read it all.
tion. To this end, the paper describes a concept-
Summarization systems usually work with a
based summarization system for biomedical doc-
representation of the document consisting of in-
uments that uses the UMLS as an external knowl-
formation that can be directly extracted from the
edge source. To address the word ambiguity prob-
document itself (Erkan and Radev, 2004; Mihalcea
lem, we have adapted an existing WSD system
and Tarau, 2004). However, recent studies have
(Agirre and Soroa, 2009) to assign concepts from
demonstrated the benefit of summarization based
the UMLS. The system is applied to the summa-
on richer representations that make use of external
rization of 150 biomedical scientific articles from
knowledge sources (Plaza et al., 2008; Fiszman et
the BioMed Central corpus and it is found that
WSD improves the quality of the summaries. This
to represent the document at a conceptual level. In
paper is, to our knowledge, the first to apply WSD
particular, in the biomedical domain Reeve et al.
to the summarization of biomedical documents
(2007) adapt the lexical chaining approach (Barzi-
and also demonstrates that this leads to an im-
lay and Elhadad, 1997) to work with UMLS con-
cepts, using the MetaMap Transfer Tool to anno-
The next section describes related work on sum-
tate these concepts. Yoo et al. (2007) represent a
marization and WSD. Section 3 introduces the
corpus of documents as a graph, where the nodes
are the MeSH descriptors found in the corpus, and
the edges represent hypernymy and co-occurrence
concept-based summarization algorithm. Section
relations between them. They cluster the MeSH
5 presents a graph-based WSD algorithm which
concepts in the corpus to identify sets of docu-
has been adapted to assign concepts from the
ments dealing with the same topic and then gen-
UMLS. Section 6 describes the experiments car-
erate a summary from each document cluster.
ried out to evaluate the impact of WSD and dis-
Word sense disambiguation attempts to solve
lexical ambiguities by identifying the correct
concluding remarks and suggests future lines of
meaning of a word based on its context. Super-
vised approaches have been shown to perform bet-ter than unsupervised ones (Agirre and Edmonds,
2006) but need large amounts of manually-taggeddata, which are often unavailable or impractical to
Summarization has been an active area within
create. Knowledge-based approaches are a good
NLP research since the 1950s and a variety of ap-
alternative that do not require manually-tagged
proaches have been proposed (Mani, 2001; Afan-
tenos et al., 2005). Our focus is on graph-basedsummarization methods. Graph-based approaches
Graph-based methods have recently been shown
typically represent the document as a graph, where
to be an effective approach for knowledge-based
the nodes represent text units (i.e. words, sen-
WSD. They typically build a graph for the text in
tences or paragraphs), and the links represent co-
which the nodes represent all possible senses of
hesion relations or similarity measures between
the words and the edges represent different kinds
these units. The best-known work in the area is
of relations between them (e.g. lexico-semantic,
LexRank (Erkan and Radev, 2004). It assumes a
fully connected and undirected graph, where each
these graphs is then applied from which a rank-
node corresponds to a sentence, represented by
ing of the senses of each word in the context is
its TF-IDF vector, and the edges are labeled with
obtained and the highest-ranking one is chosen
the cosine similarity between the sentences. Mi-
(Mihalcea and Tarau, 2004; Navigli and Velardi,
halcea and Tarau (2004) present a similar method
2005; Agirre and Soroa, 2009). These methods
where the similarity among sentences is measured
find globally optimal solutions and are suitable for
However, methods based on term frequencies
and syntactic representations do not exploit the se-
(Agirre and Soroa, 2009) which makes use of
mantic relations among the words in the text (i.e.
the PageRank algorithm used by internet search
synonymy, homonymy or co-occurrence). They
cannot realize, for instance, that the phrases my-
signs weight to each node in a graph by analyz-
ocardial infarction and heart attack refer to the
ing its structure and prefers ones that are linked to
same concepts, or that pneumococcal pneumonia
by other nodes that are highly weighted. Agirre
and mycoplasma pneumonia are two similar dis-
and Soroa (2009) used WordNet as the lexical
eases that differ in the type of bacteria that causes
knowledge base and creates graphs using the en-
them. This problem can be partially solved by
tire WordNet hierarchy. The ambiguous words in
dealing with concepts and semantic relations from
the document are added as nodes to this graph and
domain-specific resources, rather than terms and
directed links are created from them to each of
lexical or syntactic relations. Consequently, some
their possible meanings. These nodes are assigned
recent approaches have adapted existing methods
weight in the graph and the PageRank algorithm is
applied to distribute this information through the
ple, the MRREL table states that C0009443 ‘Com-
graph. The meaning of each word with the high-
mon Cold’ and C0027442 ‘Nasopharynx’ are con-
est weight is chosen. We refer to this approach
as ppr. It is efficient since it allows all ambigu-
The MRHIER table in the Metathesaurus lists
ous words in a document to be disambiguated si-
the hierarchies in which each CUI appears, and
multaneously using the whole lexical knowledge
presents the whole path to the top or root of
base, but can be misled when two of the possible
each hierarchy for the CUI. For example, the
senses for an ambiguous word are related to each
MRHIER table states that C0035243 ‘Respiratory
other in WordNet since the PageRank algorithm
Tract Infections’ is a parent of C0009443 ‘Com-
assigns weight to these senses rather than transfer-
ring it to related words. Agirre and Soroa (2009)
The Semantic Network consists of a set of cat-
also describe a variant of the approach, referred
egories (or semantic types) that provides a consis-
to as “word to word” (ppr w2w), in which a sep-
tent categorization of the concepts in the Metathe-
arate graph is created for each ambiguous word.
saurus, along with a set of relationships (or seman-
In these graphs no weight is assigned to the word
tic relations) that exist between the semantic types.
being disambiguated so that all of the information
For example, the CUI C0009443 ‘Common Cold’
used to assign weights to the possible senses of the
is classified in the semantic type ‘Disease or Syn-
word is obtained from the other words in the doc-
ument. The ppr w2w is more accurate but less
The SRSTR table in the Semantic Network de-
efficient due to the number of graphs that have to
scribes the structure of the network. This table
be created and analyzed. Agirre and Soroa (2009)
lists a range of different relations between seman-
show that the Personalized PageRank approach
tic types, including hierarchical relations (is a)
performs well in comparison to other knowledge-
and non hierarchical relations (e.g. result of,
based approaches to WSD and report an accuracy
associated with and co-occurs with).
of around 58% on standard evaluation data sets.
For example, the semantic types ‘Disease or Syn-drome’ and ‘Pathologic Function’ are connected
via the is a relation in this table.
The Unified Medical Language System (UMLS)
(Humphreys et al., 1998) is a collection of con-trolled vocabularies related to biomedicine and
The method presented in this paper consists of 4
contains a wide range of information that can
main steps: (1) concept identification, (2) doc-
be used for Natural Language Processing. The
ument representation, (3) concept clustering and
UMLS comprises of three parts: the Specialist
topic recognition, and (4) sentence selection. Each
Lexicon, the Semantic Network and the Metathe-
step is discussed in detail in the following subsec-
The Metathesaurus forms the backbone of the
UMLS and is created by unifying over 100 con-trolled vocabularies and classification systems. It
The first stage of our process is to map the doc-
is organized around concepts, each of which repre-
ument to concepts from the UMLS Metathesaurus
sents a meaning and is assigned a Concept Unique
and semantic types from the UMLS Semantic Net-
Identifier (CUI). For example, the following CUIs
are all associated with the term “cold”: C0009443
We first run the MetaMap program over the text
‘Common Cold’, C0009264 ‘Cold Temperature’
in the body section of the document1 MetaMap
(Aronson, 2001) identifies all the phrases thatcould be mapped onto a UMLS CUI, retrieves
The MRREL table in the Metathesaurus lists re-
and scores all possible CUI mappings for each
lations between CUIs found in the various sources
phrase, and returns all the candidates along with
that are used to form the Metathesaurus. This ta-ble lists a range of different types of relations, in-
1We do not make use of the disambiguation algorithm
cluding CHD (“child”), PAR (“parent”), QB (“can
provided by MetaMap, which is invoked using the -y flag(Aronson, 2006), since our aim is to compare the effect of
be qualified by”), RQ (“related and possibly syn-
WSD on the performance of our summarization system rather
onymous”) and RO (“other related”). For exam-
their score. The semantic type for each concept
a single document graph. This graph is extended
mapping is also returned. Table 1 shows this map-
with more semantic relations to obtain a more
ping for the phrase tissues are often cold. This ex-
complete representation of the document. Vari-
ample shows that MetaMap returns a single CUI
ous types of information from the UMLS can be
for two words (tissues and often) but also returns
used to extend the graph. We experimented us-
three equally scored CUIs for cold (C0234192,
ing different sets of relations and finally used the
C0009443 and C0009264). Section 5 describes
hypernymy and other related relations between
how concepts are selected when MetaMap is un-
concepts from the Metathesaurus, and the asso-
able to return a single CUI for a word.
ciated with relation between semantic types fromthe Semantic Network. Hypernyms are extracted
from the MRHIER table, RO (“other related”) re-
lations are extracted from the MRREL table, and
associated with relations are extracted fromthe SRSTR table (see Section 3). Finally, each
edge is assigned a weight in [0, 1]. This weightis calculated as the ratio between the relative posi-
tions in their corresponding hierarchies of the con-
Figure 1 shows an example graph for a sim-
plified document consisting of the two sentences
below. Continuous lines represent hypernymy re-
lations, dashed lines represent other related rela-
tions and dotted lines represent associated with re-
1. The goal of the trial was to assess cardiovascular
mortality and morbidity for stroke, coronary heart
Table 1: An example of MetaMap mapping for the
disease and congestive heart failure, as an evidence-
based guide for clinicians who treat hypertension.
2. The trial was carried out in two groups: the first
UMLS concepts belonging to very general se-
group taking doxazosin, and the second group tak-ing chlorthalidone.
mantic types are discarded, since they have beenfound to be excessively broad or unrelated to the
Our next step consists of clustering the UMLS
Quantitative Concept, Qualitative Concept, Tem-
concepts in the document graph using a degree-
poral Concept, Functional Concept, Idea or Con-
based clustering method (Erkan and Radev, 2004).
cept, Intellectual Product, Mental Process, Spatial
The aim is to construct sets of concepts strongly
Concept and Language. Therefore, the concept
related in meaning, based on the assumption that
C0332183 ‘Often’ in the previous example, which
each of these sets represents a different topic in the
belongs to the semantic type Temporal Concept, is
We assume that the document graph is an in-
stance of a scale-free network (Barabasi and Al-
bert, 1999). A scale-free network is a complex net-
The next step is to construct a graph-based repre-
work that (among other characteristics) presents a
sentation of the document. To this end, we first ex-
particular type of node which are highly connected
tend the disambiguated UMLS concepts with their
to other nodes in the network, while the remain-
complete hierarchy of hypernyms and merge the
ing nodes are quite unconnected. These highest-
hierarchies of all the concepts in the same sentence
degree nodes are often called hubs. This scale-
to construct a graph representing it. The two upper
free power-law distribution has been empirically
levels of these hierarchies are removed, since they
observed in many large networks, including lin-
represent concepts with excessively broad mean-
ings and may introduce noise to later processing.
To discover these prominent or hub nodes, we
Next, all the sentence graphs are merged into
compute the salience or prestige of each vertex
Figure 1: Example of a simplified document graph
in the graph (Yoo et al., 2007), as shown in (1).
Whenever an edge from vi to vj exists, a vote from
The last step of the summarization process con-
node i to node j is added with the strength of this
sists of computing the similarity between all sen-
vote depending on the weight of the edge. This
tences in the document and each of the clusters,
ranks the nodes according to their structural im-
and selecting the sentences for the summary based
on these similarities. To compute the similarity be-tween a sentence graph and a cluster, we use a non-
democratic vote mechanism (Yoo et al., 2007), so
that each vertex of a sentence assigns a vote toa cluster if the vertex belongs to its HVS, half a
The n vertices with a highest salience are
vote if the vertex belongs to it but not to its HVS,
and no votes otherwise. Finally, the similarity be-
first groups the hub vertices into Hub Vertices
tween the sentence and the cluster is computed as
Sets (HVS). These can be seen as set of concepts
the sum of the votes assigned by all the vertices in
strongly related in meaning, and will represent the
the sentence to the cluster, as expressed in (2).
centroids of the clusters. To construct these HVS,
the clustering algorithm first searches, iteratively
and for each hub vertex, the hub vertex most con-nected to it, and merges them into a single HVS.
Second, the algorithm checks, for every pair of
HVS, if their internal connectivity is lower than
the connectivity between them. If so, both HVS
Finally, we select the sentences for the sum-
are merged. The remaining vertices (i.e. those
mary based on the similarity between them and
not included in the HVS) are iteratively assigned
the clusters as defined above. In previous work
to the cluster to which they are more connected.
(blind reference), we experimented with different
This connectivity is computed as the sum of the
heuristics for sentence selection. In this paper, we
weights of the edges that connect the target vertex
just present the one that reported the best results.
to the other vertices in the cluster.
For each sentence, we compute a single score, as
the sum of its similarity to each cluster adjusted
are derived from the MRREL table. All possible
to the cluster’s size (expression 3). Then, the N
relations in this table are included. The output
sentences with higher scores are selected for the
from MetaMap is used to provide the list of pos-
sible CUIs for each term in a document and theseare passed to the disambiguation algorithm. We
use both the standard (ppr) and “word to word”
(ppr w2w) variants of the Personalized PageRank
It is difficult to evaluate how well the Person-
(SemGr) we have also tested two further features
alized PageRank approach performs when used
for computing the salience of sentences: sentence
in this way due to a lack of suitable data. The
location (Location) and similarity with the title
NLM-WSD corpus (Weeber et al., 2001) con-
tains manually labeled examples of ambiguous
assigns higher scores to the sentences close to the
terms in biomedical text but only provides exam-
beginning and the end of the document, while
ples for 50 terms that were specifically chosen be-
the similarity with the title feature assigns higher
cause of their ambiguity. To evaluate an approach
scores as the proportion of common concepts be-
such as Personalized PageRank we require doc-
tween the title and the target sentence is increased.
uments in which the sense of every ambiguous
Despite their simplicity, these are well accepted
word has been identified. Unfortunately no such
summarization heuristics that are commonly used
resource is available and creating one would be
(Bawakid and Oussalah, 2008; Bossard et al.,
prohibitively expensive. However, our main in-
terest is in whether WSD can be used to improve
The final selection of the sentences for the sum-
the summaries generated by our system rather than
mary is based on the weighted sum of these feature
its own performance and, consequently, decided to
values, as stated in (4). The values for the param-
evaluate the WSD by comparing the output of the
eters λ, θ and χ have been empirically set to 0.8,
summarization system with and without WSD.
The ROUGE metrics (Lin, 2004) are used to eval-
Since our summarization system is based on the
cally generated summaries (called peers) against
UMLS it is important to be able to accurately map
human-created summaries (called models), and
the documents onto CUIs. The example in Section
calculates a set of measures to estimate the con-
4.1 shows that MetaMap does not always select a
single CUI and it is therefore necessary to have
ported for the ROUGE-1 (R-1), ROUGE-2 (R-
some method for choosing between the ones that
metrics. ROUGE-N (e.g. ROUGE-1 and ROUGE-
take the first mapping as returned by MetaMap,
2) evaluates n-gram co-occurrences among the
and no attempt is made to solve this ambiguity
peer and models summaries, where N stands for
(Plaza et al., 2008). This paper reports an alter-
the length of the n-grams. ROUGE-SU4 allows
native approach that uses a WSD algorithm that
bi-gram to have intervening word gaps no longer
makes use of the entire UMLS Metathesaurus.
than four words. Finally, ROUGE-W computes
The Personalized PageRank algorithm (see Sec-
the union of the longest common subsequences be-
tion 2) was adapted to use the UMLS Metathe-
tween the candidate and the reference summaries
saurus and used to select a CUI from the MetaMap
taking into account the presence of consecutive
in which the CUIs are the nodes and the edges
To the authors’ knowledge, no specific corpus
for biomedical summarization exists. To evalu-
2We use a publicly available implementation of the Per-
ate our approach we use a collection of 150 doc-
sonalized Page Rank algorithm (http://ixa2.si.ehu. es/ukb/) for the experiments described here.
uments randomly selected from the BioMed Cen-
tral corpus3 for text mining research. This collec-
tion is large enough to ensure significant results in
the ROUGE evaluation (Lin, 2004) and allows us
to work with the ppr w2w disambiguation soft-
ware, which is quite time consuming. We generate
automatic summaries by selecting sentences untilthe summary reaches a length of the 30% over the
Table 2: ROUGE scores for two baselines and
original document size. The abstract of the papers
SemGr (with and without WSD). Significant dif-
(i.e. the authors’ summaries) are removed from
ferences among the three versions of SemGr are
the documents and used as model summaries.
A separate development set was used to deter-
mine the optimal values for the parameters in-volved in the algorithm. This set consists of 10
The use of WSD improves the average ROUGE
documents from the BioMed Central corpus. The
model summaries for these documents were man-
ppr) version of the WSD algorithm signifi-
ually created by medical students by selecting be-
cantly improves ROUGE-1 and ROUGE-2 metrics
tween 20-30% of the sentences within the paper.
(Wilcoxon Signed Ranks Test, p < 0.01), com-
The parameters to be estimated include the per-
pared with no WSD (i.e. SemGr). The “word to
centage of vertices considered as hub vertices by
word” variant (ppr w2w) significantly improves
the clustering method (see Section 4.3) and the
all ROUGE metrics. Performance using the “word
combination of summarization features used to
to word” variant is also higher than standard ppr
sentence selection (see Section 4.4). As a result,
the percentage of hub vertices was set to 15%, and
These results demonstrate that employing a
no additional summarization features (apart from
state of the art WSD algorithm that has been
the semantic-graph similarity) were used.
adapted to use the UMLS Metathesaurus improves
Two baselines were also implemented.
the quality of the summaries generated by a sum-
first, lead baseline, generate summaries by select-
ing the first n sentences from each document. The
the first result to demonstrate that WSD can im-
second, random baseline, randomly selects n sen-
prove summarization systems. However, this im-
tences from the document. The n parameter is
provement is less than expected and this is prob-
based on the desired compression rate (i.e. 30%
ably due to errors made by the WSD system.
The Personalized PageRank algorithms (ppr andppr w2w) have been reported to correctly dis-
ambiguate around 58% of words in general text(see Section 2) and, although we were unable to
Various summarizers were created and evaluated.
quantify their performance when adapted for the
First, we generated summaries using our method
biomedical domain (see Section 5), it is highly
without performing word sense disambiguation
likely that they will still make errors. However, the
(SemGr), but selecting the first CUI returned by
WSD performance they do achieve is good enough
MetaMap. Second, we repeated these experiments
to improve the summarization process.
using the Personalized Page Rank disambigua-tion algorithm (ppr) to disambiguate the CUIs re-
turned by MetaMap (SemGr + ppr). Finally, we
The results presented above demonstrate that us-
use the “word to word” variant of the Personalized
ing WSD improves the performance of our sum-
Page Rank algorithm (ppr w2w) to perform the
marizer. The reason seems to be that, since the ac-
curacy in the concept identification step increases,
Table 2 shows ROUGE scores for the different
the document graph built in the following steps is
configurations of our system together with the two
a better approximation of the structure of the doc-
baselines. All configurations significantly outper-
ument, both in terms of concepts and relations. As
form both baselines (Wilcoxon Signed Ranks Test,
a result, the clustering method succeeds in finding
the topics covered in the document, and the infor-
3http://www.biomedcentral.com/info/about/datamining/
mation in the sentences selected for the summary
is closer to that presented in the model summaries.
per from the corpus that presents an analysis tool
We have observed that the clustering method
for simple sequence repeat tracts in DNA, only
usually produces one big cluster along with a vari-
the first occurrence of ‘simple sequence repeat’
able number of small clusters. As a consequence,
though the heuristic for sentence selection was de-
maining of the document, this phrase is named
signed to select sentences from all the clusters in
by its acronym ‘SSR’. The same occurs in a pa-
the document, the fact is that most of the sentences
per that investigates the developmental expression
are extracted from this single large cluster. This
of survivin during embryonic submandibular sali-
allows our system to identify sentences that cover
vary gland development, where ‘embryonic sub-
the main topic of the document, while it occasion-
mandibular gland’ is always referred as ‘SMG’.
ally fails to extract other “satellite” information.
We have also observed that the ROUGE scores
differ considerably from one document to others.
In this paper we propose a graph-based approach
To understand the reasons of these differences we
to biomedical summarization. Our algorithm rep-
examined the two documents with the highest and
resents the document as a semantic graph, where
lowest ROUGE scores respectively. The best case
the nodes are concepts from the UMLS Metathe-
is one of the largest document in the corpus, while
saurus and the links are different kinds of seman-
the worst case is one of the shortest (6 versus 3
tic relations between them. This produces a richer
pages). This was expected, since according to our
representation than the one provided by traditional
hypothesis that the document graph is an instance
of a scale-free network (see Section 4.3), the sum-
This approach relies on accurate mapping of
marization algorithm works better with larger doc-
the document being summarized into the concepts
uments. Both documents also differ in their under-
in the UMLS Metathesaurus. Three methods for
lying subject matter. The best case concerns the
doing this were compared and evaluated.
reactions of some kind of proteins over the brain
first was to select the first mapping generated by
synaptic membranes; while the worst case regards
MetaMap while the other two used a state of the
the use of pattern matching for database searching.
We have verified that UMLS covers the vocabu-
adapted for the biomedical domain by using the
lary contained in the first document better than in
UMLS Metathesaurus as a knowledge based and
the second one. We have also observed that the use
MetaMap as a pre-processor to identify the pos-
in the abstract of synonyms of terms presented in
sible CUIs for each term. Results show that the
the document body is quite frequent. In particular
system performs better when WSD is used.
the worst case document uses different terms in the
In future work we plan to make use of the dif-
abstract and the body, for example “pattern match-
ferent types of information within the UMLS to
ing” and “string searching”. Since the ROUGE
create different configurations of the Personalized
metrics rely on evaluating summaries based on the
PageRank WSD algorithm and explore their ef-
number of strings they have in common with the
fect on the summarization system (i.e. consider-
model summaries the system’s output is unreason-
ing different UMLS relations and assigning differ-
ent weights to different relations). It would alsobe interesting to test the system with other disam-
biguation algorithms and use a state of the art al-
acronyms and abbreviations. Most papers in the
gorithm for identifying and expanding acronyms
corpus do not include an Abbreviations section but
define them ad hoc in the document body. Thesecontracted forms are usually non-standard and do
not exist in the UMLS Metathesaurus. This seri-ously affects the performance of both the disam-
This research is funded by the Spanish Govern-
biguation and the summarization algorithms, es-
ment through the FPU program and the projects
pecially considering that it has been observed that
TIN2009-14659-C03-01 and TSI 020312-2009-
the terms (or phrases) represented in an abbrevi-
44. Mark Stevenson acknowledges the support of
ated form frequently correspond to central con-
the Engineering and Physical Sciences Research
C.-Y. Lin. 2004. Rouge: A package for automatic eval-
uation of summaries. In Proceedings of the ACL-
S.D. Afantenos, V. Karkaletsis, and P. Stamatopou-
04 Workshop: Text Summarization Branches Out.,
ments: a survey. Artificial Intelligence in Medicine,33(2):157–177.
I. Mani. 2001. Automatic summarization. Jonh Ben-
E. Agirre and P. Edmonds, editors, 2006.
Sense Disambiguation: Algorithms and Applica-
R. Mihalcea and P. Tarau. 2004. TextRank - Bringing
order into text. In Proceedings of the ConferenceEMNLP 2004, pages 404–411.
E. Agirre and A. Soroa. 2009. Personalizing PageRank
for Word Sense Disambiguation. In Proceedings of
R. Navigli and P. Velardi. 2005. Structural seman-
EACL-09, pages 33–41, Athens, Greece.
tic interconnections: A knowledge-based approachto word sense disambiguation. IEEE Trans. Pattern
A. Aronson. 2001. Effective mapping of biomedi-
Anal. Mach. Intell., 27(7):1075–1086.
cal text to the UMLS Metathesaurus: the MetaMapprogram. In Proceedings of the AMIA Symposium,
S. Nelson, T. Powell, and B. Humphreys. 2002. The
Unified Medical Language System (UMLS) Project. In Allen Kent and Carolyn M. Hall, editors, Ency-
A. Aronson. 2006. MetaMap: Mapping text to the
clopedia of Library and Information Science. Mar-
UMLS Metathesaurus. Technical report, U.S. Na-
L. Plaza, A. D´ıaz, and P. Gerv´as.
A.L. Barabasi and R. Albert. 1999. Emergence of scal-
graph based biomedical automatic summarization
ing in random networks. Science, 268:509–512.
using ontologies. In TextGraphs ’08: Proceedingsof the 3rd Textgraphs Workshop on Graph-Based Al-
gorithms for Natural Language Processing, pages
chains for text summarization. In Proceedings of the
ACL Workshop on Intelligent Scalable Text Summa-rization, pages 10–17.
L.H. Reeve, H. Han, and A.D. Brooks. 2007. The
use of domain-specific concepts in biomedical text
summarization. Information Processing and Man-
summarization system: University of Birmingham
at TAC 2008. In Proceedings of the First Text Anal-ysis Conference (TAC 2008).
M. Weeber, J. Mork, and A. Aronson. 2001. Devel-
oping a Test Collection for Biomedical Word Sense
A. Bossard, M. Gnreux, and T. Poibeau. 2008. De-
Disambiguation. In Proceedings of AMIA Sympo-
scription of the LIPN systems at TAC 2008: sum-
sium, pages 746–50, Washington, DC.
marizing information and opinions. In Proceedingsof the First Text Analysis Conference (TAC 2008).
graph-based semantic clustering and summarization
S. Brin and L. Page. 1998. The anatomy of a large-
approach for biomedical literature and a new sum-
scale hypertextual web search engine.
marization evaluation method. BMC Bioinformat-
Networks and ISDN Systems, 30:1–7.
G. Erkan and D. R. Radev. 2004. LexRank: Graph-
based lexical centrality as salience in text summa-rization. Journal of Artificial Intelligence Research(JAIR), 22:457–479.
M. Fiszman, T. C. Rindflesch, and H. Kilicoglu.
2004. Abstraction summarization for managing thebiomedical research literature.
the HLT-NAACL Workshop on Computational Lex-ical Semantics, pages 76–83.
L. Humphreys, D. Lindberg, H. Schoolman, and
guage System: An informatics research collabora-tion. Journal of the American Medical InformaticsAssociation, 1(5):1–11.
Language Processing: Perspective Whats BeyondPubMed? Mol Cell., 21(5):589–594.
Q&A ABORTO PROVOCADO (agosto de 2011) Preguntas y respuestas acerca de la política holandesa sobre el aborto provocado. El folleto ‘Q&A Aborto Provocado’ responde a las preguntas que pueda tener el lector extranjero acerca de la legislación holandesa sobre el aborto. Esta publicación electrónica ha sido elaborada en colaboración con el Ministerio de Sanidad, Bienestar y Dep
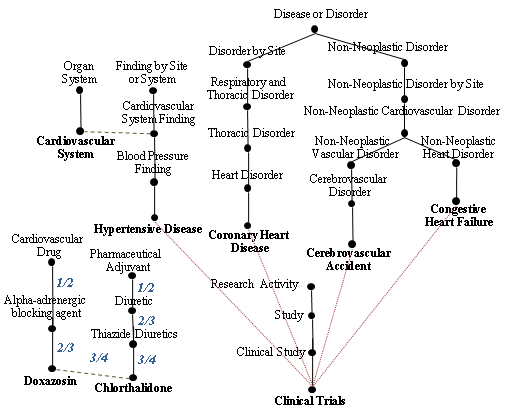 Figure 1: Example of a simplified document graph
in the graph (Yoo et al., 2007), as shown in (1).
Figure 1: Example of a simplified document graph
in the graph (Yoo et al., 2007), as shown in (1).