Tadalafil zeigt eine konstante Resorption im Gastrointestinaltrakt, mit maximalen Plasmaspiegeln nach rund zwei Stunden. Der Wirkstoff verteilt sich gut im Gewebe und weist eine hohe Plasmaproteinbindung auf. Seine lange Halbwertszeit erlaubt eine verlängerte Wirkphase. Der Metabolismus erfolgt über das hepatische Enzymsystem CYP3A4, mit der Bildung inaktiver Metaboliten. Exkretion geschieht primär über den Stuhl. Die Häufigkeit von Nebenwirkungen steigt mit der Dosis, wobei vor allem vasodilatatorische Effekte dominieren. Ein gängiger Bezugspunkt in pharmakologischen Analysen ist cialis ohne rezept, das mit dieser Wirkstoffklasse assoziiert ist.
Microsoft word - 03-cruz-koniec.doc
COMPUTATIONAL METHODS IN SCIENCE AND TECHNOLOGY 11(2), 101-108 (2005) Mail filtering on medium/huge mail servers with j-chkmail José-Marcio Martins da Cruz Ecole des Mines de Paris – 60, bd St. Michel B 75272 Paris e-mail: Jose-Marcio.Martins@ensmp.fr Abstract: Mail filtering on huge servers is a very difficult problem, mainly in regard to efficiency and security. A filter presenting excellent results when running on small or medium servers may present deceiving results when used on huge servers. This paper presents an approach mixing behaviour and content-analysis to scale some filtering methods on huge servers. Key words: mail filtering, huge mail servers, greylisting, behavioural mail filtering 1. INTRODUCTION
90% the quantity of spam on email traffic over Internet. It is not unusual to find people getting 100, 200 and even more
Ten years ago, as soon as Internet really began its large-
spam messages each day inside their mailboxes.
scale deployment, malicious users immediately understood that this communication vector could easily be used to achieve their goals.
2. MEDIUM/HUGE SERVERS
Probably, the first large, malicious usage of Internet was
By medium/huge mail servers, we're talking about mail
the massive sending of messages to unlimited recipients. In
servers used by many thousands of users, handling hundreds
the early days, bandwidth was an issue. So spammers1 began
of thousands connections a day. Mail filtering constraints on
using open-relays2. This was nearly immediately solved both
huge servers are not the same as those on small and medium
by the generalisation of anti-relaying control on mail servers,
servers. Some filtering-related constraints are:
software and by the appearance of RBLs3. But, in those days,
diversity – user profiles on a big university campus
the real big problems were the load imposed to open relays
may be very diversified: social sciences, economics, computer
and the amount of non-delivery notifications (bounces) science, physicians, management . This diversity implies that
one cannot define a typical mailbox: a global typical mailbox
Some time later, viruses appeared, using messaging sys-
tems to spread themselves. The new era began with Melissa
doesn't match individual mailboxes and vice-versa.
[CERT99] and LoveLetter [CERT00]. Since then, viruses
Scalability – it is easy to build a system handling, say,
have been the big threat, as they can really generate 50 000 connections a day for 1000 final users. But the goal is irreversible damage to information systems and user data.
that needed computing doesn't grow faster than traffic level.
Usual solutions found for this problem were the generalisation
Surges – huge mail servers will have to have enough spare
of virus scanners on both users’ computers and on mail
resources in order to “adequately” handle unattended events,
servers. This was the first real content-filtering feature added
such as bursts of messages or connections.
to mail servers. Virus scanning on mail servers is a very
factors – interactions between administrators of
servers and final users are simpler in small and medium size
• interpreting the message and extracting its on-line content
organisations: usually they personally know each other.
Getting the user-feedback and reliable information needed to
• examining each extracted part and looking for the pres-
tune the filter is much easier on small systems.
ence of virus signatures (usual database size is around
Low level constraints – these are the limitations at hard-
ware or operating system-level, usually forgotten on small
Meanwhile, spam activity increased to a very high level.
systems: the number of processes running on the system, disk
Nowadays, some Internet Service Providers (ISPs) estimate at
I/O bandwidth, network I/O bandwidth, etc.
architecture – at big sites, filtering is usually done at
1 Spam – general expression making reference to unsolicited electronic
gateways, not mail storage servers. Usually, they don't have
any information about users other than its existence.
2 Open relays – mail servers accepting the relay of messages from any
Reliability/availability – on huge servers, downtime
3 RBL – Realtime BlackList: DNS-based list of open relays and spam
3. MAIL FILTERING Bayesian filters – The incoming message is broken down
into small units [PG02] and a spam rating is then computed
It is common to classify mail filters in two categories:
for each unit, based on the frequency they appear on the
content and behaviour filtering, but it is not always easy or
typical user mailbox. Some filters use words as the basic unit,
possible to set up a clear separation between them.
but others filters had found different ways to categorise text.
The efficiency of Bayesian filters is usually very high,
3.1.Content filtering
especially if applied to individual mailboxes or to a homo-
Content filtering is based on the analysis of data found in-
side message bodies or envelopes. Methods range from Although they seem very different, Bayesian and heuristic
simple pattern matching to complex language processing.
filters share a common characteristic: they are classifiers.
Let us present some of them, but limit the discussion to
Statistical classifiers learn what the user mailbox is. The ef-
methods which can be found in j-chkmail.
ficiency of classifiers is optimal when the incoming traffic
matching – this is probably the most basic filter
perfectly matches the mailbox used in the learning phase.
we can use. The goal is to verify if one or more regular
This requirement cannot usually be satisfied on servers
expressions from some defined list may be found in the mes-
handling messages for a heterogeneous community.
sage. If yes, then the message may be rejected or some score
If we see the classification process as being a distance
may be assigned to it. The cost of this kind of filtering is very
high as each expression has to be matched against the whole
• Higher distances between spam- and ham-typical mail-
message. The filter is unusable if more than some few boxes will result in better classification.
hundred expressions are defined. Required effort to maintain
• Sending legitimate messages with characteristics found in
lists of expressions is very important as, e.g., the same word
a spam mailbox will increase the false positive rate.
may appear with many variants (viagra, v1agra, vi@gra, .). It
We shall remark here that some very reliable filtering
is very difficult to automate the pattern extraction task if we
criteria, such as URL blacklists, are sometimes included in
want, at the same time, to minimise the number of expressions
heuristic filters and the weight assigned to them are evaluated
in the process of error rate optimisation. This isn't always
filtering – this method is a variant of the previous,
the best choice, as this kind of criteria is independent of
but much more efficient. Arriving messages are scanned once
typical mailbox categorization and, most of the time, may
in order to extract all URLs. The domain part of URLs is then
have absolute weights assigned to them, instead of being
looked up at some database. SURBL [JC04] is one of evaluated by an optimisation process.
the most effective non-commercial URL databases available: it lists a more than 120 000 domains, its effectiveness is better
3.2. Behaviour filtering
than 80% and FP rate4 lower than 0.5%. SURBL is available
Behaviour analysis tries to detect messages or SMTP
as a DNS zone, but may also be used as a local database
clients behaving in a way different from the one found in
normal situations. Such deviations may be of many kinds, such
Heuristic filters – the most well known heuristic filter is
as, compliance to usual technical standards or “non-human”
SpamAssassin [SA05]. Each message is submitted to a large
behaviour of SMTP clients. Most of the time, behaviour
set of checks (some hundreds), such as the presence/absence
analysis implies analysis over some sliding time window, which
of some headers, html coding quality, the presence of implies saving each connection/message parameter. Time-a cryptographic signature, matching mime boundaries fields
window size depends on the behaviour being checked.
against some regular expression, etc. Some of these tests fall
Connection rate is an example of analysis in a relative
short time-interval. Sending messages by a human being is
Each successful test will additively contribute to the mes-
a stochastic process: time interval between two messages is
random variable with exponential distribution. Spam
Weights assigned to each test are evaluated in a way to
messages sent by robots looks like bursts. Connection rate
minimise the probability of error in a corpus of messages re-
analysis is done within a sliding time window of five to
presenting a typical user mailbox. So, ‘message score evalua-
twenty minutes length. Setting a limit on the connection rate is
tion’ is a kind of distance measurement – how far the arriving
a simple way of avoiding bursts of connections.
message is from the user typical legitimate message.
Greylisting [EH03] is an example of behaviour analysis
Recent SpamAssassin versions removed most checks with
over a longer period. RFC 2821 [RFC2821] specifies that an
a negative score. Checks with both positive and negative
SMTP client shall retry message delivery after a temporary
weights are an issue as score-evaluation is not monotonic and
rejection. So, the idea is simple: when the message arrives for
all checks need to be performed, even if only few tests are
the first time, it is rejected with a temporary error result. If
the message is proposed again some time later, after some
minimum delay, it will be accepted. This makes the assump-
4 FP Rate – False Positive Rate – the rate at which a non-spam message is
tion that spam robots do not perform error handling and will
Mail filtering on medium/huge mail servers with j-chkmail
not retry later. Greylisting time-window size ranges from
spam traps”, and “sending messages with high content spam
score” are behaviours stored at medium lifetime history.
RBLs are another example of an even bigger time-win-
SMTP clients presenting these behaviours are blacklisted for
dow: one day to some weeks. These lists are usually consti-
four hours. SMTP clients doing too many connections over
tuted by the IP addresses of computers which were seen
a ten minute sliding window are blacklisted for ten minutes
sending spam in the past few days – but most of the time, this
and until its connection rate falls into a normal value.
Take the filter decision as soon as possible – content
Nowadays, behaviour checking does not detect too much
handling is much heavier than behaviour and envelope
spam. The reason is that more and more spammers are trying
handling. So, if you can decide what to do during early phases
to use armies of zombies 5 to send their messages and disguise
of SMTP dialogue (before DATA command) do not wait.
their activity. A master zombie controller dispatches to each
That is to say – do behaviour filtering instead of content filter-
zombie a message and a list of many thousands of recipients.
Lists are created in a way to avoid having too many recipients
Compromise between doing well and doing fast – while
in the same domain. This way, each SMTP server will see
some filter techniques are very efficient, their cost is too high.
very few connections coming from each zombie, and will not
High cost methods shall be avoided unless their contribution
have enough data to do behaviour analysis. Only some to the global filter effectiveness is big enough. external observer with a privileged point of view of all the ac-
Avoid external dependencies – external dependencies
tivity of the zombie will be able to detect the unusual activity
are the source of two kind of problem: latency delays (which
increases the connection handling time) and vulnerabilities –
Either way, behaviour analysis remains useful to detect
your system may stop answering if some external resource
DoS 6 and other evident deviation of normal behaviour.
Close long lasting connections – many misconfigured 4. SCALING MAIL FILTERING
SMTP clients or spam bots close TCP connection without quitting the SMTP session, leaving servers with useless
Let us consider “filter scalability” as the filter ability to
connections open. For most MTAs, each open connection
increase the traffic level handled with a reasonable increase in
corresponds to a different process. If the number of processes
its resources consumption. In other words, resources usage
becomes too high, an SMTP server may present scheduling
will grow, at most, linearly with traffic level.
problems. Generally speaking, all kind of long operations
Some precautions need to be taken when building a high-
should be avoided, even if they do not consume CPU cycles.
performance filter. Some points are related to the filter itself,
and others to the MTA. Let us recall some of them.
4.1.Efficient content filtering Learn while working – To achieve scalability, one idea
is to use some length of history to decide, if possible, at
The data in Table 1 can help us understand what happens
connection time, if the server will accept the message or not.
on a huge server. The important point about the data coming
The sooner the connection is rejected, the less it contributes to
from this filter is that all filtering checks are done at the same
the server load: this way, the marginal connection-handling
point: after the SMTP DATA command. This ensures that all
cost decreases with the number of connections already checks are done and we can compare them. This is not true handled for the same SMTP client.
for filters like j-chkmail, where connections may be rejected
Filter results will be observed for each SMTP client, and
at early phases and one cannot know what could happen to
stored in memory. To optimise memory usage, j-chkmail uses
these messages if all checks were performed. The data in this
table summarises six hours of activity of prolocation.net mail
• short history (some minutes) the filter stores some figures
servers, and presents the twenty-five more frequent filtering
• medium history (some hours) – the filter stores some
As we can see, the most efficient criteria are URL black-
figures for each SMTP client presenting some suspect or bad
lists, IP blacklists and Bayesian filtering. Heuristic criteria
appear less frequently and come from non-reliable checks
• long history (some days) – some data about SMTP clients
(HTML message). The very most effective criterion is URL
presenting confirmed bad behaviour is extracted from log files
filtering. Pattern matching appears once with very low hit-
and stored in local databases, used by the filter.
count, but is probably a good spam indicator.
These classes of history correspond to some kind of
Another important point to note is the existence of
dynamic blacklist management, e.g., “sending messages to
external dependencies: fifteen blacklists found among the
twenty-five top hits. This point shows, for this filter, how
5 Zombies – these are computers controlled by spammers to send spam.
important external sources of data are. To minimize server-
Usually, they are end user computers infected by some virus allowing
dependability from external factors, a local copy of these lists
someone to remotely install and control applications on it.
Table 1. The twenty-five most frequent filtering criteria
Message whitening is left to recipients, based on their address
book. Some level of false positives may be accepted if they
can be easily identified by recipients. • Filter efficacy's is better measured by user's ease of mes-
sage classification – subjective criteria.
• Regular expressions and URL filtering methods generates
very few false positives, if correctly configured, as they represent patterns only found on spams and not on hams.
Weights assigned to these checks may be high enough to trig-
Heuristics filtering basically checks message compliance
with respect to RFCs and to check some characteristics
frequently appearing on spams. There are only 32 tests of this
kind on current j-chkmail release and this number is falling.
4.2. Combining content and behaviour filtering to achieve scalability
Behaviour/content co-operation may appear in both direc-
tions. When the score of a behaviour check is high but not
enough to reject the connection, it can set up some initial
On the other hand, gateways sending messages with high
scores will have this information stored inside medium term
history and will reduce behaviour thresholds applied to these
If co-operation appears very interesting, care shall be
taken to avoid closed loops, in which case the filter may
The most interesting case of co-operation between content
and behaviour filtering comes from greylisting.
5. ADAPTIVE DELAY GREYLISTING
Greylisting is the last filtering method added to j-chkmail
and its implementation is a very interesting example of co-
operation between filtering methods. In its basic version, it
presents excellent filtering results but its scalability is limited. There are two problems with basic greylisting:
Database size grows with recipient rate, not connection
rate. Our tests were validated on a gateway handling around
500 K connections per day. Normal database size for this
gateway is around 600 K records, but we have seen some peaks of 1 M records. Grey databases need periodic scanning to
From this, a good strategy for content filtering is:
remove old records and, given the size of databases, access
• URL filtering is very effective and will be a primary
times may become prohibitive on huge servers. Some filters use
disk-based databases (relay-delay [RD03], milter -gris [MG04a]
• It makes no sense to evaluate, with extreme precision,
and j-chkmail), while milter -greylisting [MG04b] uses a linked
weights assigned to heuristic criteria if a typical mailbox
list (in memory) to store the greylisting database;
cannot be defined. And, as they are not either highly effective
Database poisoning attacks are possible on greylisting
or reliable, this heuristic filtering will be a secondary method.
filters. A malicious remote user may be able to fill up the fil-
Weights assigned to checks may be based on an estimation of
ter database if he does lots of connections and tries to send
messages to many recipients from random senders. It is
• Whitening checks will be minimised. Most of the time,
enough to try to send a thousand messages to the same
whitening criteria on filters may be abused by spammers, and
thousand recipients with a different sender each time to create
good whitening criteria are not usually the same for all users.
a million entries at the server side greylisting database.
Mail filtering on medium/huge mail servers with j-chkmail
Milter-greylisting partially addresses the first issue: white-
the triplet. There is no reason for, e.g., bounce triplets to have
listed entries may use only a client IP address part of the same lifetime than normal message triplets, or triplets the triplet if configured to.
from SMTP clients sending virus or spam to have the same
Adaptive Delay Greylisting tries to address these two
lifetime as normal message triplets. Also, why should
the triplet 192.97.20.2!joe@terena.nl!joe@ensmp.fr
(erasmus.terena.nl) be handled with the same priority as 209.67.208.34!joe@terena.nl!joe@ensmp.fr (34.208.67.209.
Daily dist ribut ion of wait ing t riplet s
reverse.layeredtech.com)? In both cases, the sender is some-
one in the domain “terena.nl”, but only the first one come
• Greylisting database entries – data inside a single record
may determine if its lifetime will be shortened or not. Examples of data taken into account are: the message is
a bounce, the SMTP client address doesn't resolve or the re-
verse/direct resolutions do not match, or the SMTP client host name and message sender domain name do not match.
• Greylisting database as a whole – correlating entries
from the same source or analysing how old entries are dropped may be enough to detect well or badly behaving
sources – and allow management of simple black or white
lists. Database poisoning may be avoided if a limit is set on
Fig. 1. Daily distribution of the number of triplets
the number of recent waiting triplets generated by the same
source. Examples of criteria are: the number of waiting
triplets from this source and the number of different domains
Figure 1 shows a sample of the daily distribution of
waiting entries at jussieu.fr mail gateway. This example shows
• Cooperation with external filters – recent whitelisted or
two probable data poisoning attacks on the first two days.
waiting triplets from some SMTP client may be removed if
The first question we can ask ourselves is: how many
content filtering applied to recent messages from this SMTP
entries are validated after they remain waiting for more than
client results in spam most of the time. Examples of criteria
a specific time? An easy way to answer this question is to
are: the mean spam score of messages coming from this
sample the waiting database at some specific time intervals
SMTP client in the past or the number of viruses coming from
(say six hours), create the time distribution of entries and
superpose results from different samples. This way, we can
have an idea of the number of entries being validated.
Data from domain ensmp.fr shows that the number of
waiting triplets validated when they are older than twelve hours is always smaller than 1%. We can interpret this result as the usefulness of database records: 99% of the number of entries older than twelve hours is useless. Another, much more conservative evaluation makes the assumption that all entries older than one day are useless. With this point of view, we can consider up to 80% the of database records are useless when the maximum waiting time is five days.
The above analysis allows us to set up higher and lower
limits on our goals. Even the lower limit is very interesting for database sizes with greater than 500 K entries.
So, the question that adaptive delay greylisting tries to
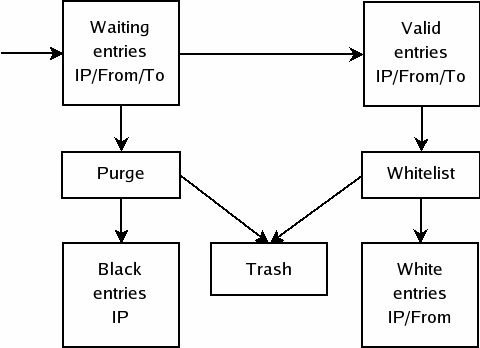
Fig. 2. Adaptive Delay Greylisting data flow
answer is: how will we select the records to be removed?
Basic greylisting filters use three time constants [EH03]:
An adaptive Delay Greylisting data flow schema is pre-
the minimum delay to accept waiting triplets, and the maxi-
sented in Fig. 2. Two databases are added to original grey-
mum lifetime for waiting and whitelisted triplets. The basic
listing schema: white- and black-entries databases. Valid
idea of Adaptive Delay Greylisting is that time constants are
entries database replace the original white entries database.
not fixed but depend on some “quality” score assigned to
The lifetime for both valid and black entries may be lowered
down to a week. White entries are generated from single or
False positive and message loss rate may increase, as it
multiple valid entries with very good behaviour. On the con-
may happen that legitimate waiting triplets are removed from
trary, black entries come from waiting entries with very bad
the waiting-entries database before they come back. But in
behaviour and may be used by other filtering methods.
this case, when they come back, another greylisting cycle will
At the time of writing, only results for database cleaning-
be started. If, even after this new cycle, the client cannot
-up based on information internal to the database itself are
deliver its message, it is reasonable to think that he is
available. Co-operation with content and behaviour filtering is
suffering from some scheduling problem (other than the initial
implemented but the algorithms have not been validated reason the triplet was removed). sufficiently.
False negative rate will decrease. In traditional greylisting,
Results below considers the lifetime of entries are reduced
false negatives may happen when some waiting triplet is
the same way, no matter which reducing criterion is matched,
validated some days later by some message which is not the
but this isn't necessary. The action applied to the entry may
initial one. As Adaptive Delay Greylisting removes suspicious
also vary depending on which reducing criterion is matched:
entries, this situation will become less frequent than before.
while some criteria may generate a reduction on the entry
lifetime, others may immediately delete the entry from
6. RESULTS
database (e.g., a virus found on a recent message accepted from this SMTP client).
6.1 Results of behaviour filtering
An interesting presentation of results is given in Table 2.
Results of behaviour filtering are more difficult to evalu-
This table shows the daily distribution of the number of
ate. In a normal operation, the ratio between spam blocked by
waiting triplets in the database, when the lifetime of suspi-
behaviour filtering itself (no external information sources and
cious triplets is reduced to 6, 12 or 24 hours. In all cases, the
no greylisting) and content filtering itself varies between 10
number of waiting triplets is limited to 1000 for each SMTP
and 20%. So, it does not really contribute too much to reduce
the server-load under usual conditions. This can be explained
We can see from this table that the size of the database
by the fact that much spam is sent by zombies and behaviour
may be drastically reduced even if the lifetime of suspicious
filtering isn't very effective against this kind of SMTP client.
On the other hand, behaviour filtering remains very
interesting to block surges of spam or surges of viruses. At
Table 2. Reduction results of a waiting triplets-database: daily
ensmp.fr domain we estimate that, when the MyDoom virus
distribution of the number of records against the lifetime of suspi-
begun spreading, at least half of incoming viruses were
Table 3. Reduction results of a valid triplets-database
Table 3 shows how valid database size is reduced when its
useless content is discarded and its useful content is distrib-uted over itself and white database. Note that 7967 entries from the valid entries database are converted into 1326 entries on the white entries database, as this last one stores only IP/From information.
We have seen that Adaptive Delay Greylisting allows
reduction of database size. But what would be the influence
Fig. 3. Connection rate control in action: incoming and rejected connections. Bursts of connections are rejected without disturbing
over other parameters, mainly spam detection and error-rate?
Mail filtering on medium/huge mail servers with j-chkmail
Figure 3 shows how two bursts of 20 K connections done
In this case, if his MUA performs the pre-filtering algorithm
in ten minutes are smoothed for specific clients. It is re-
shown above, he will need to correct only 4.4 messages a day,
markable that as long as the connection rate limit is done on a
per-IP-basis, all connections from other sources arriving
within this time interval were not disturbed.
6.3. Server Load
This goal was fully attained: j-chkmail is a filter which
6.2. Results of content filtering
does not consume too many system resources. Table 5
These results, presented in Table 4, come from all presents some typical values of load. Note that the much messages received by the author over fifteen days. This test
bigger consumption of memory with Linux. The reason is the implementation of threads with Linux and the memory
was done as follows: messages arriving are sent to the normal
user mailbox and a copy is redirected to a test the account in
an IMAP server using a sieve filter to redirect them to one of three mailboxes. Filtering is done after greylisting.
Table 4. Results of content filtering classification over fifteen days
allocated, which grows very fast with the number of threads.
This is already reduced by using an alternative implementa-
tion of libmilter [JM03], based on a pool of workers instead
A score greater than zero means that the message matched
These results need some interpretation. This data was
7. CONCLUSIONS
collected from the author’s mailbox. The author is a computer scientist, and his mailbox-type may not match other profiles
Mail filtering on huge servers is difficult. While it is easy
which will surely give different results.
to do reliable filtering for small or homogeneous medium
The results above are not as bad as one would think, as
communities, very few filtering techniques are ready to fill
they result from the Aheavy@ filtering on the server. All ham
messages, whose score is greater than 0, come from discus-
j-chkmail implements some ways to handle important
sion lists (some of them are related to spam filtering) and can
traffic levels, but does not achieve efficiency and the low
be pre-filtered (add a personal criteria: he knows the sender),
error-rates found on well-tuned personal filters.
However, j-chkmail is a convenient solution if we accept a
reasonable goal which is more qualitative than quantitative -
ease of classification of messages by the final user instead of
some very high numeric measurement of efficiency. This is
possible if users accept finding, from time to time, some spam
messages among their legitimate messages. It is more a human
If we were to select the more effective features implemen-
• Connection rate control (and other similar controls) do not
block too much spam, but are very interesting to protect the
Most false negatives come from 419/SCAM messages
server against unattended traffic surges.
which are difficult to filter without high false positive rates.
• Greylisting: at least for the moment, this is a very interest-
Results are worse than those we can obtain with Bayesian
ing technique as it blocks most spam, with very few false
filters, but we shall note that this result is scalable as no
positives. Ideas presented in this paper help with the scaling
assumption was done about the categorisation of the user’s
mailbox, and on the other hand, this content filtering was
• URL filtering – The main criterion used by Surbl.org to
applied to messages which had already passed a greylisting
manage its URL blacklist, “If it appears in HAM, do not list
it” makes it very interesting as it does not depend on a typical
Either way, one can see the efficiency of the filter as
user mailbox – a big problem at important organisations.
the difficulty the final user has to correctly class his mailbox.
Surbl.org is, at the same time, fast, efficient and reliable.
Acknowledgments
E. Haris, The Next Step in the Spam Control War: Greylisting,
Many people contributed to this work, but the author wants to
http://www.greylisting.org/articles/whitepaper.shtml
thanks those who specifically contributed in many ways to aspects
[JM03a] Jose M. M. Cruz, Le filtrage de mail sur un serveur
related to mail filtering on huge servers: mainly Tibor Weis
de messagerie avec j-chkmail, JRES2003
(pobox.sk and tuzvo.sk) and Sebastien Vautherot (jussieu.fr). But
also Jeff Chan (surbl.org), Raymond Dijkxhoorn (prolocation.net
[MG04a] milter-gris Web Site,
and surbl.org), Dennis Peterson, Christian Pelissier (onera.fr) and
[MG04b] milter-greylisting Web Site, http://hcpnet.free.fr/milter
References
http://projects.puremagic.com/greylisting
http://www.cert.org/advisories/CA 1999 -04.html
http://www.cert.org/advisories/CA2000 -04.html
7 JOSE-MARCIO MARTINS DA CRUZ holds an Electrical Engineer degree from Instituto Tecnologico de Aeronautica – Brazil (1978), a MSc in Electrical Engineering (Cryptography) from Universidade de Brasilia – Brazil (1983) and a MSc in Computer Science (Distributed Computing) from INT-Evry (1995). He currently works at Ecole des Mines de Paris and his main interests are mail filtering, security, network monitoring, intrusion detection and cryptography. He's the author of j-chkmail (a mail filter described in this paper) and vigilog (a set of scripts used to analyse router log files in order to detect scans).
COMPUTATIONAL METHODS IN SCIENCE AND TECHNOLOGY 11(2), 101-108 (2005)
PUERTO RICO WATER RESOURCES AND ENVIRONMENTAL Date of the report: December 2nd , 2005 For Quarter Ending: December, 2005 Project Tittle: ‘Removal of Inorganic, Organic and Antimicrobials Contaminants from Aqueous Solutions by Waste Tire Crumb Rubber’ Name of Contact (PI): Oscar Perales-Perez Telephone : 1-787-8324040 (3087) Fax: 1-787-265-8016 E-mail: oscar@ge.uprm.edu Na
Internet: www.figcparma.it e-mail: presidenza@figcparma.it Via F. Lombardi, 6 - C.P. 463 - 43100 Parma – Tel. 0521 27.16.71 - 0521 27.15.31 Fax: 0521 27.29.88 Risponditore: 0521 77.87.42 Comunicato Ufficiale n. 27 pubblicato il 14 Gennaio 2009 1. COMUNICAZIONI DELLA DELEGAZIONE PROVINCIALE Causa il permanere dell’innevamento dei campi di giuoco tutte le gare programmate per SABATO
 Mail filtering on medium/huge mail servers with j-chkmail
Milter-greylisting partially addresses the first issue: white-
the triplet. There is no reason for, e.g., bounce triplets to have
listed entries may use only a client IP address part of the same lifetime than normal message triplets, or triplets the triplet if configured to.
from SMTP clients sending virus or spam to have the same
Adaptive Delay Greylisting tries to address these two
lifetime as normal message triplets. Also, why should
the triplet 192.97.20.2!joe@terena.nl!joe@ensmp.fr
(erasmus.terena.nl) be handled with the same priority as 209.67.208.34!joe@terena.nl!joe@ensmp.fr (34.208.67.209.
Daily dist ribut ion of wait ing t riplet s
reverse.layeredtech.com)? In both cases, the sender is some-
one in the domain “terena.nl”, but only the first one come
• Greylisting database entries – data inside a single record
Mail filtering on medium/huge mail servers with j-chkmail
Milter-greylisting partially addresses the first issue: white-
the triplet. There is no reason for, e.g., bounce triplets to have
listed entries may use only a client IP address part of the same lifetime than normal message triplets, or triplets the triplet if configured to.
from SMTP clients sending virus or spam to have the same
Adaptive Delay Greylisting tries to address these two
lifetime as normal message triplets. Also, why should
the triplet 192.97.20.2!joe@terena.nl!joe@ensmp.fr
(erasmus.terena.nl) be handled with the same priority as 209.67.208.34!joe@terena.nl!joe@ensmp.fr (34.208.67.209.
Daily dist ribut ion of wait ing t riplet s
reverse.layeredtech.com)? In both cases, the sender is some-
one in the domain “terena.nl”, but only the first one come
• Greylisting database entries – data inside a single record 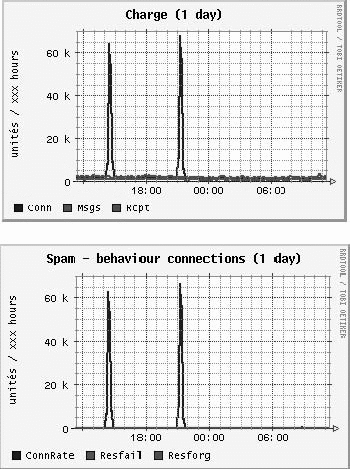 down to a week. White entries are generated from single or
False positive and message loss rate may increase, as it
multiple valid entries with very good behaviour. On the con-
may happen that legitimate waiting triplets are removed from
trary, black entries come from waiting entries with very bad
the waiting-entries database before they come back. But in
behaviour and may be used by other filtering methods.
this case, when they come back, another greylisting cycle will
At the time of writing, only results for database cleaning-
be started. If, even after this new cycle, the client cannot
-up based on information internal to the database itself are
deliver its message, it is reasonable to think that he is
available. Co-operation with content and behaviour filtering is
suffering from some scheduling problem (other than the initial
implemented but the algorithms have not been validated reason the triplet was removed). sufficiently.
False negative rate will decrease. In traditional greylisting,
Results below considers the lifetime of entries are reduced
false negatives may happen when some waiting triplet is
the same way, no matter which reducing criterion is matched,
validated some days later by some message which is not the
but this isn't necessary. The action applied to the entry may
initial one. As Adaptive Delay Greylisting removes suspicious
also vary depending on which reducing criterion is matched:
entries, this situation will become less frequent than before.
while some criteria may generate a reduction on the entry
lifetime, others may immediately delete the entry from
6. RESULTS
down to a week. White entries are generated from single or
False positive and message loss rate may increase, as it
multiple valid entries with very good behaviour. On the con-
may happen that legitimate waiting triplets are removed from
trary, black entries come from waiting entries with very bad
the waiting-entries database before they come back. But in
behaviour and may be used by other filtering methods.
this case, when they come back, another greylisting cycle will
At the time of writing, only results for database cleaning-
be started. If, even after this new cycle, the client cannot
-up based on information internal to the database itself are
deliver its message, it is reasonable to think that he is
available. Co-operation with content and behaviour filtering is
suffering from some scheduling problem (other than the initial
implemented but the algorithms have not been validated reason the triplet was removed). sufficiently.
False negative rate will decrease. In traditional greylisting,
Results below considers the lifetime of entries are reduced
false negatives may happen when some waiting triplet is
the same way, no matter which reducing criterion is matched,
validated some days later by some message which is not the
but this isn't necessary. The action applied to the entry may
initial one. As Adaptive Delay Greylisting removes suspicious
also vary depending on which reducing criterion is matched:
entries, this situation will become less frequent than before.
while some criteria may generate a reduction on the entry
lifetime, others may immediately delete the entry from
6. RESULTS  Acknowledgments
Acknowledgments