Tadalafil zeigt eine konstante Resorption im Gastrointestinaltrakt, mit maximalen Plasmaspiegeln nach rund zwei Stunden. Der Wirkstoff verteilt sich gut im Gewebe und weist eine hohe Plasmaproteinbindung auf. Seine lange Halbwertszeit erlaubt eine verlängerte Wirkphase. Der Metabolismus erfolgt über das hepatische Enzymsystem CYP3A4, mit der Bildung inaktiver Metaboliten. Exkretion geschieht primär über den Stuhl. Die Häufigkeit von Nebenwirkungen steigt mit der Dosis, wobei vor allem vasodilatatorische Effekte dominieren. Ein gängiger Bezugspunkt in pharmakologischen Analysen ist cialis ohne rezept, das mit dieser Wirkstoffklasse assoziiert ist.
Data hiding by lsb substitution using discrete wavelet transform
ISSN: 2229-6956(ONLINE) ICTACT JOURNAL ON SOFT COMPUTING, APRIL 2012, VOLUME: 02, ISSUE: 03
AN EFFECTIVE SPAM FILTERING FOR DYNAMIC MAIL MANAGEMENT SYSTEM S. Arun Mozhi Selvi1 and R.S. Rajesh2 1Department of Information Technology, Dr. Sivanthi Aditanar College of Engineering, India 2Department of Computer Science and Engineering, Manonmaniam Sundaranar University, India Abstract
for major retail outlets and small artisans and traders. Business-
Spam is commonly defined as unsolicited email messages and the goal
to-business and financial services on the Internet affect supply
of spam categorization is to distinguish between spam and legitimate email messages. The economics of spam details that the spammer has to target several recipients with identical and similar email messages. 1.2 EMAIL As a result a dynamic knowledge sharing effective defense against a substantial fraction of spam has to be designed which can alternate
Electronic mail, commonly called email or e-mail, is a
the burdens of frequent training stand alone spam filter. A weighted
method of exchanging digital messages across the Internet or
email attribute based classification is proposed to mainly focus to
other computer networks. Originally, email was transmitted
encounter the issues in normal email system. These type of
directly from one user to another computer. This required both
classification helps to formulate an effective utilization of our email
computers to be online at the same time, a la instant messaging.
system by combining the concepts of Bayesian Spam Filtering Algorithm, Iterative Dichotmiser 3(ID3) Algorithm and Bloom Filter.
Today's email systems are based on a store-and-forward model.
The details captured by the system are processed to track the original
Email servers accept, forward, deliver and store messages. Users
sender causing disturbances and prefer them to block further mails
no longer need be online simultaneously and need only connect
from them. We have tested the effectiveness of our scheme by
briefly, typically to an email server, for as long as it takes to
collecting offline data from Yahoo mail & Gmail dumps. This
send or receive messages. An email message consists of two
proposal is implemented using .net and sample user-Id for knowledge
components, the message header, and the message body, which
base.
is the email's content. The message header contains control
information, including, minimally, an originator's email address
Keywords:
and one or more recipient addresses and the body contains the
Spam, Bayesian, IMAP, ID3
message itself as unstructured text; sometimes containing a signature block at the end. This is exactly the same as the body
1. INTRODUCTION
of a regular letter. The header is separated from the body by a blank line.
In this modern society all are spending their most of the time
with internet, the reason behind this is it provides a easy way of
1.3 HOW SPAM FILTERING SYSTEM WORKS
communication with the people where ever they are and also people find a way for buying and selling their product through
There is no one specific algorithm for statistically
internet to make money without wasting their time as much as.
determining whether or not a given e-mail message is in fact a
The main criterion for this is Providing Security. Especially the
spam message. As discussed earlier, the most prominent
email system is suffered with degraded quality of service due to
approach to spam classification involves the implementation of
rampant spam and fraudulent emails. Thus in order to avoid
the Bayesian chain rule, also known as Bayesian filtering.
these types of problem a system is needed to extract only the needful information for the user as per his/her requirement and
1.4 MOTIVATION
preferences. By doing this most of the unwanted mails from the
The Existing system still confuses us in working with our
mail user agent can be filtered to our notice which will be a great
mailbox. The major part of the page holds the unwanted
use for the user while viewing their regular mails.
newsletters and advertisement Though there are certain packages
1.1 INTERNET
helpful to extract the needful information they are not up to the users full satisfaction and also act as a spyware which totally
The Internet is a global system of interconnected computer
upset’s the user. There exists a strong call to design high-
networks that use the standard Internet Protocol Suite (TCP/IP) to
performance email filtering systems. A careful analysis of spam
serve billions of users worldwide. It is a network of networks that
shows that the requirements of an efficient filtering system
consists of millions of private, public, academic, business, and
include: (1) accuracy (2) self-evolving capability (3) high-
government networks, of local to global scope, that are linked by
performance which needs to be completed quickly especially in
a broad array of electronic and optical networking technologies.
large email or messaging systems. We are motivated by the
The Internet carries a vast range of information resources and
inadequate classification speed of current anti-spam systems.
services, such as the inter-linked hypertext documents of the
Data have shown that the classification speeds of current spam
World Wide Web (WWW) and the infrastructure to support
filters fall far behind the growth of messages handled by servers.
electronic mail. The Internet has enabled or accelerated new
Based on this a system has to be proposed for an efficient spam
forms of human interactions through instant messaging, Internet
forums, and social networking. Online shopping has boomed both
S ARUN MOZHI SELVI AND R S RAJESH: AN EFFECTIVE SPAM FILTERING FOR DYNAMIC MAIL MANAGEMENT SYSTEM
2. BACKGROUND AND RELATED WORKS
By the inadequate classification speed of current anti-spam
SMTP Protocol
systems data have shown that the classification speeds of current
Processing
spam filters fall far behind the growth of messages handled by servers. Based on this a system has to be proposed for an
efficient spam filtering. From [1] the Decision tree data mining
technique is chosen to classify the mails based on the any score or weight. From [2] Hash based lookup for the token in the scan
Tokenisation Database
list is chosen to improve the speed and efficiency. From [3] the basic spam filtering process for parsing the tokens of each mail in an effective manner. From [4] learnt to adapt the system under
White list, Black
partial online supervision so that the efficiency may be improved
on usage. From [5] a new concept of categorizing the mail into an unclassified category which is neither SPAM nor HAM.
Occurrence
Thus based on the survey made a system should act as an
Statistics
interface to the mail server and classifies mails as per the user’s requirements. Mails, the user always want to read are placed
Statistical
under regular and those mails the user never wants to read are
Algorithm
placed under spam. The unexpected mails that the user wants to get but which are not much important can be placed under suspected mails. Thus based on this classification can be done by
an effective filtering mechanism by combining the concepts of
Classification
Bayesian Spam Filtering Algorithm, Iterative Dichotmiser 3 Algorithm and Bloom Filter. Owing to this a system is created as a knowledge base for spam tokens which repeatedly occur in the
spam mails. The probability of occurrence of such tokens are
Fig.1. Work flow of the Spam Filtering System
calculated using Bayesian algorithm and the output of it will be the input to the bloom filter which assigns weight for those
1.5 PROBLEM STATEMENT
tokens for the easy lookup in the knowledge base. Based on the above information and several attributes like From_Id, Subject,
Most of the existing research focuses on the design of
Body, To_Id, Sender’s IP Address the mails are further
protocols, authentication methods; neural network based self-
classified into three categories as White_List (HAM),
learning and statistical filtering. In contrast, we address the spam
Gray_List(SUSPECTED) , Black_List (SPAM) with a help of
filtering issues from another perspective – improving the
id3 algorithm. These type of classification helps to formulate an
effectiveness by an efficient algorithm. They focus only towards
effective utilization of our email system. This proposal is
the better improvement of acquiring the mail box information
implemented using .net and sample user-Id for knowledge base.
from spam mails. This system is mainly to overcome the difficulties faced by the current mail server agents. The system
3. PROPOSED MECHANISM
acts as an interface to the mail server and captures the mail information as per the user’s requirement which in turn avoids
Based on the survey related to classification an effective
advertisement, unwanted mails from reading and wasting the
spam filtering mechanism is proposed by combining the
time working with large stuff of information dumped in mailbox.
concepts of Bayesian Algorithm, Iterative Dichotmiser 3
A weighted email attribute based classification is proposed to
Algorithm, weighted attribute algorithm and Bloom Filter.
mainly focus to encounter the issues in normal email system. It
Owing to this a system is created as a knowledge base for spam
makes the user to feel more securable by means of detecting and
tokens which repeatedly occur in the spam mails. The
classifying such malicious mails when the user checks the inbox
probability of occurrence of such tokens are calculated using
by notifying with different colors for spam (red), suspected
Bayesian algorithm and the output of it will be the input to the
(blue) and ham (green) mails. These type of classification helps
bloom filter which assigns weight for those tokens for the easy
to formulate an effective utilization of our email system.
lookup in the knowledge base. Based on the above information
1.6 OVERVIEW OF THE PAPER
and several attributes like From_Id, Subject, Body, To_Id, Sender’s IP Address the mails are further classified into three
The thesis is organized as follows section 2 the background
categories as White_List (HAM), Gray_List(SUSPECTED),
and motivation of this research with the help of reference paper
Black_List (SPAM) with a help of ID3 algorithm. These type of
and internet. Section 3 introduces the proposed mechanism
classification helps to formulate an effective utilization of our
which describes the major work. Section 4 describes the
email system. This proposal is implemented using .net and
The mechanism flows through the following stages,
ISSN: 2229-6956(ONLINE) ICTACT JOURNAL ON SOFT COMPUTING, APRIL 2012, VOLUME: 02, ISSUE: 03
tokens with spam and non-spam e-mails and then using Bayesian
Learning Training Filtering Acquisition
statistics to calculate the probability that an e-mail is spam or
not. Rather than calculating the probability for all the tokens in
the message. The list of spamminess tokens are identified by different users and evaluated for the scan list both for the subject and body of the message.
3.1 DATA ACQUISITION PHASE
In this phase the no of mails of 4 different users are studied
3.3 TRAINING PHASE
and the way they are categorized is captured. This Information is
Calculate the prob
acquired from the Google and Yahoo dumps as they suffer a lot
Weight calculation for spammiminess
from the different types of spam. About 200 mails are analyzed
Database of tokens #
and the mail Information retrieved from the current mail servers
(probability value is
are extracted to and given to the next Learning Phase. Based on
calculated based on
the Acquired data on different e-mail accounts, the following
Bayesian algorithm)
sample is shown in Table.1. From the subjects, it can be noted that some of the unwanted mails are under Ham mails (i.e.
inbox). The analysis shows that 50% of the mails come under ham and the remaining 50% comes under spam. For example,
3.3.1 Probability Calculation for Spamminess Tokens
“New SBI security update”, “ICICI bank home loan” even
Bayesian Theorem:
though these mails are not much important they are under
To calculate the probability using Bayesian Theorem, first it
regular mail. Hence in order to reduce the amount of unwanted
needs to calculate the probability for individual words which is
mails in inbox, an idea to classify the mails into a new category
likely to be spam. This is calculated by using the following
called suspected was decided. This category holds the mails that
are not much important and they can be viewed separately at the user’s convenience.
Pr(S/W) probability that a message is spam knowing
Pr(S) overall probability that any given message is
Pr(W/S) probability that the word “x” appears in spam
Pr(H) overall probability that any given message is not
Pr(W/H) probability that the word “x” appears in ham
3.3.2 Weight Calculation Based on Bloom Filter:
In order to find the spamminess of the mail, a Bloom filter
concept called weight methodology is introduced. The weight is
calculated on the basis of the probability values calculated and
the severity of the tokens that were analyzed during the learning
phase. The weight methodology was obtained from the concept
of bloom filter. In the Bloom filter, each tokens probability is
considered to be associated with value ‘w’ for storing and
retrieving, when used at the end to calculate a message’s spamminess, a token’s probability value ‘w’ is approximately
3.2 LEARNING PHASE
mapped back to p. The value “w” represents the weight here.
The weight is calculated with a simple equation:
Identifying the Analysis Extraction of tokens from header fields studied mails
P = Probability of the token to be spam
W = Weight assigned for the easy lookup
Bayesian Spam filtering is a statistical technique of e-mail
The following table shows the sample individual tokens of
filtering. It makes use of naive base classifiers to identify spam
both subject fields, body their probability and weight for
e-mails. Bayesian classifiers work by correlating the use of
S ARUN MOZHI SELVI AND R S RAJESH: AN EFFECTIVE SPAM FILTERING FOR DYNAMIC MAIL MANAGEMENT SYSTEM
Table.2 Acquired information Sample P and W value for the
CRITICAL ATTRIBUTES:
tokens found in both subject and body field
Attribute 1 Spam List 1: Spam id and Subject Subject Probability Weight Probability Weight 0: Opposite situation Attribute 2 "To id" 1: Not my id mark 0: Opposite situation Attribute 3 Contact List
The calculated weight is rated from 1 to 10 and the
1: From id not in Contact List
Threshold value is 5. The weight for each token is calculated in
0: Opposite situation
the Learning phase as per the severity of the token made in the
Attribute 4 Subject contains Abnormal Keywords
analysis. The above values (token, probability, weight) both for
1: Presence of Abnormal Keywords
subject and body are stored into database for further filtering.
0: Opposite situation Attribute 5 Size of the Mail 3.4 FILTERING PHASE 1: No more than 6kB 0: Opposite situation
The details learnt and calculated in the previous phase are
Attribute 6 Body checking
given as the input to this filtering phase.
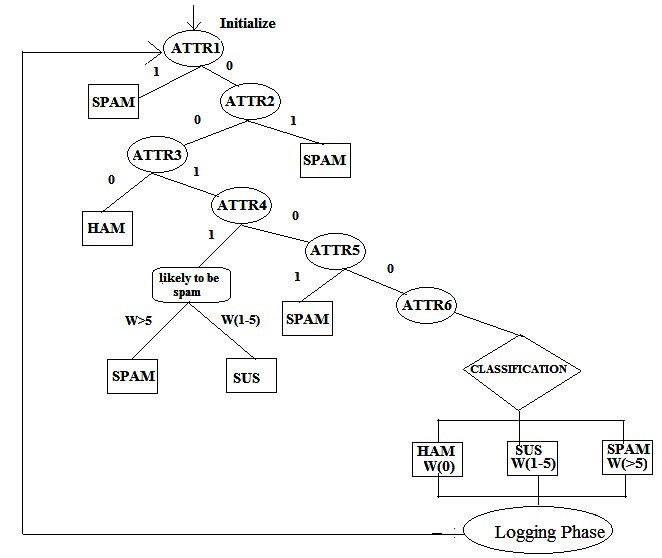
CLASSIFICATION 3.4.1 Filtering Algorithm (A Weighted Attribute Algorithm TARGET ATTRIBUTES: and ID3):
The various header fields (critical attributes) and the message
(usually body) are given as an input to the filtering algorithm –
SUSPECTED
the algorithm used here to filter and classify the mails is Iterative Dichotmister3 (ID3). It is mathematical algorithm for building
Fig.6. List of Attributes for ID3 Algorithm
the decision tree. The tree should be built from the top to down, with no backtracking.
Step 1: Checks the List of Spam id and Subject if 1 classifies as 3.4.1.1 A Weighted Attribute Algorithm(WAA): Step 2: Checks the TO id with user id if 1 step3 0 classifies as A Step 3: Check with contact List if 1 classifies as A 0 step4
If the message has the weight (w = 0), then it means Ham
Step 4: Check with subject scan list if 1goto WAA 0 step5 Step 5: Check size <6kB 1classifies as C 0 step6
If the message has the weight (w = 1 to 5), then it means
Step 6: Check with body scan list if 1 goto WAA 0 classifies as A
If the message has the weight (w > 5), then it means
The cumulative weight is calculated in the algorithm when it
reaches the Step 4 and Step 5 so that when the weight reaches
the threshold the algorithm directly classifies rather than
If any one condition is satisfied it exits the main
checking all the tokens, thus improves the efficiency.
3.4.1.2 ID3 Algorithm: 3.5 LOGGING PHASE Database Filter for future (suspected subjects & id)
This is the phase where all the details are logged in a file for
3.5.1 Monitoring Database:
The database table contains the suspected id and subject,
which is stored from the mail that has already came to the inbox which is filtered out and then classified that it is spam. So, in future when the mails are coming from the same id are with the same subject is automatically redirected to the spam folder instead of checking the mails with all critical attributes and then finally redirects to the spam folder. This makes the filtering process much more efficient to the mail server.
ISSN: 2229-6956(ONLINE) ICTACT JOURNAL ON SOFT COMPUTING, APRIL 2012, VOLUME: 02, ISSUE: 03
4. IMPLEMENTATION
The proposed mechanism was implemented in .net platform
and SQL server with the help of the 4 sample user’s and their id. Based on the feedback of those sample users’s the analysis is
Current mail classification based on the no of mails
Proposed Mail Classification based on the no of mails
False positive Analysis for current mail server versus
False Negative Analysis for current mail server versus
Accuracy Analysis for current mail server versus
5. RESULT ANALYSIS Sample id's
Fig.9. Proposed Mail Classification based on the no of Mails
Id1 = heyaruna@gmail.com, Id2 = zainabasiya@yahoo.co.uk,
Id4 = karthiga24@yahoo.in, Id5 = muthulakshmiit27@gmail.com Analysis are made by the User’s feedback for each mail id
Sample Id's
Fig.10. False positive Analysis for current mail server vs.
Sample id's
Fig.8. Current mail classification based on the no of mail
Sample Id's
Fig.11. False Negative Analysis for current mail server vs.
S ARUN MOZHI SELVI AND R S RAJESH: AN EFFECTIVE SPAM FILTERING FOR DYNAMIC MAIL MANAGEMENT SYSTEM
False Positive (FP) – Classifying or identifying a ham mail as
Based on the implementation results the false positives and false
negatives can be reduced gradually with the help of the logging
False Negative (FN) – Classifying or identifying a spam mail as
phase in acquiring the original sender details. Based on this the
Accuracy is also improved for large dataset.
8. FUTURE ENHANCEMENT
This proposal can be enhanced with more no of samples with
more efficient Data Mining Technique. The implementation can
be worked out in the mails servers for testing the effectiveness of
REFERENCES
[1] Jhy-Jian Sheu “An Efficient Two-Phase Spam Filtering
Method Based on E-mail Categorization”, International Journal of Network Security, Vol. 9, No. 1, pp.34-43, 2009.
[2] Zhenyu Zhong and Kang Li “Speed Up Statistical Spam
Filter by Approximation”, IEEE Transactions on Computers, Vol. 60, No. 1, pp. 120 – 134, 2011.
Sample Id's
[3] Yan Luo, “Workload Characterization of Spam Email
Filtering System”, International Journal of Network
Fig.12. Accuracy Analysis for current mail server vs. proposed
Security and its Application, Vol. 2, No. 1, pp. 22 – 41,
6. DISCUSSION
Androutsopoulos “Adaptive Spam Filtering Using Only Naïve Bayes Text Classifiers”, Spam Filtering Challenge
Thus from the above results it can be inferred that the % of
Competition, Fifth Conference on Email and Anti-Spam,
false positives and false negatives in the current mail servers can
be reduced. The Accuracy is also improved for large dataset.
[5] Brian whitworth and Tong Liu, “Channel E-mail: A
Thus it can be concluded that the major part of the inbox in
Sociotechnical Response to Spam”, IEEE Computer
current mail server is with spam messages which are
Society, Vol. 42, No. 7, pp. 63-71, 2009.
considerably avoided in the proposed Algorithm.
[6] Naresh Kumar Nagwani and Ashok Bhansali “An object
oriented Email clustering model using weighted similarities
7. CONCLUSION
between email attributes”, International Journal of research and reviews in Computer Science, Vol. 1, No. 2,
This proposal is mainly to focus to encounter the issues in
normal email system. These types of classification help to formulate an effective utilization of our current email system.
MINISTRY OF AGRICULTURE AND RURAL DEVELOPMENT NATIONAL AGRO-FORESTRY-FISHERIES QUALITY ASSURANCE DEPARTMENT The Residues Monitoring Program for Certain Harmful Substances in aquaculture fish and products thereof in 2009 and Implementation Plan in 2010 RESULTS OF THE MONITORING PROGRAM FOR CERTAIN HARMFUL 1. General The Program for control of residues in farmed fish has
HOBO® U22 Water Temp Pro v2 (Part # U22-001) The HOBO Water Temp Pro v2 logger is designed with a durable, streamlined, UV-stable case for extended deployments measuring temperature in fresh or salt water. The small size of the logger allows it to be easily mounted and/or hidden in the field. It is waterproof up to 120 m (400 feet) and rugged enough to withstand years of use, even in
 S ARUN MOZHI SELVI AND R S RAJESH: AN EFFECTIVE SPAM FILTERING FOR DYNAMIC MAIL MANAGEMENT SYSTEM
Table.2 Acquired information Sample P and W value for the
CRITICAL ATTRIBUTES:
S ARUN MOZHI SELVI AND R S RAJESH: AN EFFECTIVE SPAM FILTERING FOR DYNAMIC MAIL MANAGEMENT SYSTEM
Table.2 Acquired information Sample P and W value for the
CRITICAL ATTRIBUTES: