Tadalafil zeigt eine konstante Resorption im Gastrointestinaltrakt, mit maximalen Plasmaspiegeln nach rund zwei Stunden. Der Wirkstoff verteilt sich gut im Gewebe und weist eine hohe Plasmaproteinbindung auf. Seine lange Halbwertszeit erlaubt eine verlängerte Wirkphase. Der Metabolismus erfolgt über das hepatische Enzymsystem CYP3A4, mit der Bildung inaktiver Metaboliten. Exkretion geschieht primär über den Stuhl. Die Häufigkeit von Nebenwirkungen steigt mit der Dosis, wobei vor allem vasodilatatorische Effekte dominieren. Ein gängiger Bezugspunkt in pharmakologischen Analysen ist cialis ohne rezept, das mit dieser Wirkstoffklasse assoziiert ist.
Ece.uci.edu
Distributed Embedded Systems for Low Power: A Case Study
University of California, Irvine, CA 92697-2625,
Abstract
scheduling techniques. As DVS reaches its limit on a singleprocessor, researchers turn to multiple processors to create
A multiple-processor system can potentially achievehigher energy savings than a single processor, because
Multiple processors can potentially achieve higher en-
the reduced workload on each processor creates new op-
ergy savings than a single processor. By partitioning the
portunities for dynamic voltage scaling (DVS). However,
workload onto multiple processors, each processor is now
as the cost of communication starts to match or surpass
responsible for only a fraction of the workload and can op-
that of computation, many new challenges arise in making
erate at a lower voltage/frquency level with quadratic power
DVS effective in a distributed system under communication-
saving. Meanwhile, the lost performance can be compen-
intensive workload. This paper discusses implementation
sated by the increased parallelism. Another advantage with
issues for supporting DVS on distributed embedded pro-
a distributed scheme is that heterogeneous hardware such as
cessors. We implemented and evaluated four distributed
DSP and other accelerators can further improve power effi-
schemes: (1) DVS during I/O, (2) partitioning, (3) power-
ciency of various stages of the computation through special-
failure recovery, and (4) node rotation. We validated the re-
ization. Although a tightly-coupled, shared-memory multi-
sults on a distributed embedded system with the Itsy pocket
processor architecture may have more power/performance
computers connected by serial links. Our experiments con-
advantages, they are not as scalable as distributed, message-
firmed that a distributed system can create new DVS op-portunities and achieve further energy savings. However,
While distributed systems have many attractive proper-
a surprising result was that aggregate energy savings do
ties, they pay a higher price for message-passing communi-
not translate directly into a longer battery life. In fact, the
cations. Each node now must handle not only I/O with the
best partitioning scheme, which distributed the workload
external world, but also I/O on the internal network. Pro-
onto two nodes and enabled the most power-efficient CPU
gramming for distributed systems is also inherently more
speeds at 30–50%, resulted in only 15% improvement in
difficult than for single processors. Although higher-level
battery lifetime. Of the four techniques evaluated, node ro-
abstractions have been proposed to facilitate distributed
tation showed the most measurable improvement to battery
programming, these abstraction layers generate even more
lifetime at 45% by balancing the discharge rates among the
inter-processor communication traffic behind the scenes.
While this may be appropriate for high-performance clus-ter computers with multi-tier, multi-gigabit switches likeMyrinet or Gigabit Ethernet, such high-speed, high-powercommunication media are not realistic for battery-powered
Introduction
embedded systems. Instead, the low-power requirementhave constrained the communication interfaces to much
Dynamic voltage scaling (DVS) is one of the most stud-
slower, often serial interfaces such as I2C and CAN. As a
ied topics in low-power embedded systems.
result, even if the actual data workload is not large on an
CMOS characteristics, the power consumption is propor-
absolute scale, it appears expensive relatively to the com-
tional to V 2; while the supply voltage V is linearly propor-
putation performance that can be delivered by today’s low-
tional to the clock frequency. To fully exploit such quadratic
power vs. voltage scaling effects, previous studies have ex-
The effect of I/O on embedded systems has not been
tensively explored DVS with real-time and non-real-time
well studied in existing DVS works. Many existing DVS
techniques have shown impressive power savings on a sin-
We also use Itsy’s on-board power instrumentation features
gle processor. However, few results have been fully qual-
to collect data for the power characteristics. Our results
ified in the context of an entire system. Even fewer have
confirmed that the distributed DVS scheme combined with
been validated on actual hardware. One common simplify-
efficient load balancing by rotating the nodes achieved the
ing assumption is to ignore I/O. Embedded systems (includ-
highest measured energy saving and extended the battery
ing single-processor systems) that perform no I/O are not
realistic. I/O can actually enhance computation by creat-ing opportunities for DVS through parallelism. At the sametime, I/O can also compete with computation for time and
Related Work
power budgets, thereby lowering the limit on power savingsachievable by DVS. The effects of I/O on DVS is not yetwell understood, and the problem is further complicated bythe trend towards DVS in distributed systems.
Real-time scheduling has been extended to DVS
The contributions of this paper are two-fold.
scheduling on variable-voltage processors.
we demonstrate the gap between CPU-centric DVS claims
scheduling model was introduced by Yao et al [10], then ex-
and actual attainable power savings by implementing
tended and refined by Yasuura [6], Quan [7] and many stud-
a full-featured distributed embedded system running a
ies in variations for real-time scheduling problems. Since
communication-bound, communication-intensive workload
power is a quadratic function of the supplying voltage, low-
with expensive I/O. This work also contrasts with sensor
ering the voltage can result in significant savings while
networks, which may be distributed, networked, and low-
still enabling the processor to continue making progress
power, but they are 99% idle, perform very little computa-
such that the tasks can be completed before their deadlines.
tion and communication, and are soft real-time. Our case
These techniques often focus on the energy reduction to the
study considers much higher computation workload under
processor only; while the power consumption of other com-
tight timing constraints. Without much slack, DVS cannot
ponents, including memory, I/O, is ignored. The results are
be very effective, but the expensive I/O turns out to be a new
DVS has been applied to benchmark applications such
Our second contribution is the set of principles and pit-
as JPEG and MPEG in embedded systems. Im et al [4] pro-
falls in global power optimization. Our findings confirmed
poses to buffer the incoming tasks such that the idle period
that parallelism can indeed create new opportunities for
between task arrivals can be utilized by DVS. Shin et al [8]
DVS to achieve further energy savings; however, one must
introduces an intra-task DVS scheme that maximally uti-
avoid many pitfalls in order to achieve these savings on a
lizes the slack time within one task. Choi et al [2] presents
distributed architecture powered by separate batteries. A
a DVS scheme in an MPEG decoder by taking advantage of
single battery failure can be disastrous to the entire sys-
the different types of frames in the MPEG stream. These
tem. We observed that global energy optimization can often
techniques can be validated with measurement on real or
contradict the goal to maximize the uptime of a distributed,
emulated platforms. However, they are also computation-
battery-powered system. This is due to the fact that global
oriented such that the processor performs only very little, if
optimization does not guarantee a locally near-optimal con-
any I/O. The impact of I/O still remains under-studied.
figuration for each distributed node. An ill-configured node
DVS has recently been extended to multi-processor sys-
operating at an energy-inefficient point can drain its battery
tems. Weglarz [9] proposes partitioning the computation
quickly and bring down the whole system. Our experiments
onto a multi-processor architecture that consumes signif-
indicated load balancing is one of the key factors in decid-
icantly less power than a single processor.
ing the uptime of the first faulting node. Special considera-
fundamental difference in applying techniques for multi-
tions, including partitioning, scheduling, synchronization,
processors to distributed systems. Minimizing the global
load balancing and power failure detection and recovery,
energy consumption will extend the battery life only if the
must be carefully coordinated with DVS, or else the same
whole system is assumed to be powered by a single battery
DVS techniques will be counterproductive.
unit. In a distributed environment, each node is power by
This paper first reviews DVS techniques, the application
a dedicated battery. Even a globally optimal solution may
example, and the experimental platform. We chose the Itsy
cause poor battery efficiency locally and result in shortened
pocket computer as our experimental platform: it supports
system uptime as well as loss of battery capacities. Maleki
a rich, well-documented set of DVS routines, and it is also
et al [5] analyzes the energy efficiency of routing proto-
available to other researchers who wish to reproduce these
cols in an ad-hoc network and shows that the global optimal
results. Because Itsy runs Linux, it is easy to port full-
schemes often contradicts the goal to extend the lifetime of
fledged, distributed programs and experimental tools to it. Figure 1. Block diagram of the ATR algorithm. Figure 2. The timing vs. power diagram of a single node. Motivating Example Figure 3. The timing vs. power diagram of two nodes.
We select an image processing algorithm, automatic tar-
get recognition (ATR) as our motivating example to evalu-ate a realistic application under I/O pressure. Its block di-agram is shown in Fig. 1. The algorithm is able to detectpre-defined targets on an input image. For each target, aregion of interest is extracted and filtered by templates. Fi-nally, the distance of each target is computed. A throughput
When multiple nodes are configured as a distributed sys-
constraint is imposed such that the image frames must be
tem, we organize them in a pipeline for the ATR algorithm.
Fig. 3 shows the timing vs. power diagram of two pipelined
We evaluate a few DVS schemes on one or more em-
nodes performing the ATR algorithm. Node1 maps first two
bedded processors that perform the ATR algorithm. Un-
function blocks, and Node2 performs the other two blocks.
like many DVS studies that ignore I/O, we assume that all
Node1 receives one frame from the data source, and it pro-
nodes in our system are connected to a communication net-
cesses the data and sends the intermediate result to Node2
work. This network carries data from external sources (e.g.,
in D seconds. After Node2 starts receiving from Node1, it
a camera, sensor, etc.) internal communications between
finishes its share of computation and sends the final result
the nodes, and to an external destination (e.g., a PC). This
to the destination within D seconds. Fig. 3 shows that if the
study assumes only one image and one target are processed
data source keeps producing one frame every D seconds,
at a time, although a multi-frame, multi-target version of the
and both Node1 and Node2 can send their results also in D
seconds, then the distributed pipeline is able to provide one
We refer to each embedded processor as a node. A node
result in every D seconds to the destination.
is a full-fledged computer system with a voltage-scalableprocessor, I/O devices, and memory. Each node performs
We use generic TCP/IP sockets to implement reliable
a computation task PROC and two communication tasks
communication, although it could be further optimized. We
RECV and SEND. RECV receives data from the external
believe this is reasonable and is much lighter weight than
source or another node. The data is processed by PROC,
middleware such as CORBA, which some researchers advo-
which consists of one or more functional blocks of the ATR
cate even on small devices. We also assume the workload of
algorithm. The result is transmitted by task SEND to an-
the algorithm is fixed such that DVS opportunities are lim-
other node or the destination. Due to data dependencies,
ited by I/O and timing constraints. Our purpose in this study
tasks RECV , PROC, and SEND must be fully serialized for
is to explore the computation-I/O interaction and their im-
each node. In addition, they must complete within a time
pact on DVS, but not to specifically optimize for either I/O
period called the frame delay D, which is defined as the per-
power or computation power. Other techniques that reduce
formance constraint. Fig. 2 illustrates the timing vs. power
communication or computation power under variable work-
load can be readily brought into the context of this study. Figure 5. Networking multiple Itsy units with a host computer. Figure 4. The block diagram of Itsy [1]. Experimental Platform
transparently as if they were on the same TCP/IP network. The network configuration is shown in Fig. 5.
We use the Itsy pocket computers as distributed nodes,
The serial link might not be the best choice for inter-
connected by a TCP/IP network over serial links.
connect, but it is often used in real life due to power con-
present the performance and power profiles of the ATR al-
straints. A high-speed network interface requires several
gorithm running on Itsy computers and define the metrics
Watts of power, which is too high for battery-powered em-
In this paper, our primary goal is to investigate the
The Itsy Pocket Computer
new opportunities for DVS-enabled power vs. performancetrade-offs in distributed embedded systems with intensive
The Itsy pocket computer is a full-fledged miniaturized
I/O. Given the limitations of serial ports, we do not intend
computer system developed by Compaq Western Digital
to propose our experimental platform as a prototype of a
Lab [1, 3]. It supports DVS on the StrongARM SA-1100
new distributed network architecture. We chose this net-
processor with 11 frequency levels from 59 – 206.4 MHz
work platform primarily because it represents the state of
over 43 different voltage levels. Itsy also has 32MB flash
the art in power management capabilities. It is also consis-
memory for off-line storage and 32MB DRAM as the main
tent with the relatively expensive communication, both in
terms of time and energy, seen by such systems. We ex-
lithium-ion battery pack. Due to the power density con-
pect that our findings in this paper can be applied to many
straint of the battery, Itsy currently does not support high-
communication-intensive applications on other network ar-
speed I/O such as Ethernet or USB. The applicable I/O ports
chitectures, where communication is a key factor for both
are a serial port and an infra-red port. Itsy runs Linux with
networking support. Its block diagram is shown in Fig. 4. Performance Profile of the ATR Algorithm Network Configuration
Each single iteration of the entire ATR algorithm takes
We currently use the serial port as the network interface.
1.1 seconds to complete on one Itsy node running at the
We set up a separate host computer as both the external
peak clock rate of 206.4 MHz. When the clock rate is re-
source and destination. It connects the Itsy nodes through
duced, the performance degrades linearly with the clock
multiple serial ports established by USB/serial adaptors. We
rate. The PPP connection on the serial port has a maximum
setup individual PPP (point-to-point protocol) connections
data rate of 115.2 Kbps, though our measured data rate is
between each Itsy node and the host computer. Therefore
roughly 80 Kbps. In addition, the startup time for establish-
the host computer acts as the hub for multiple PPP net-
ing a single communication transaction takes 50–100 ms.
works, and it assigns a unique IP address to each Itsy node.
The computation and communication behaviors are profiled
Finally, we start the IP forwarding service on the host com-
and summarized in Fig. 6. The functional blocks can be all
puter to allow Itsy nodes to communicate with each other
combined into one node or distributed onto multiple nodes
long delays thus consume a significant amount of energy,
although the communication power level is not the highest.
As a result, I/O energy becomes a primary target to optimizein addition to DVS on computation.
We evaluate several DVS techniques by a series of ex-
periments with one or more Itsy nodes. A baseline config-uration is a single Itsy node running the entire ATR algo-
Figure 6. Performance profile of ATR on Itsy.
rithm at the highest clock rate. It is able to produce oneresult in every D seconds. For all experiments, we fix this
frame delay D as the performance constraint and keep theItsy node(s) running until the battery is fully discharged.
The energy metric can be measured by the battery life T (N)when N nodes with N batteries are being used. The com-pleted workload F(N) is the number of frames completedbefore the battery exhaustion. The battery life in the base-
Current (mA)
line configuration is T (1). Since the frame delay D is fixed,
the host computer will transmit one frame to the first Itsynode in every D seconds. The Itsy node(s) are also able to
complete and send one result back to the host in every Dseconds. In an N-node pipeline, there is a pipeline startup
delay (N − 1) × D before the first result can be produced. Therefore, T (N) = F(N) × D + (N − 1) × D. Since F(N)
Freq (MHz)
is at least a few thousand frames in our experiments while
N = 2, the pipeline startup overhead is ignored such that
Communication Computation T (N) = F(N) × D.
The battery life T (N) is also called the absolute batteryFigure 7. Power profile of ATR on Itsy. life. We also define the normalized battery life Tnorm(N) =T (N)/N to quantify the energy savings for fair compar-isons. The rationale behind this distinction is that, the to-
in a pipeline. In the single node case there are no communi-
tal lifetime of N batteries should be at least N times that of
cations between adjacent nodes, although the node still has
a single battery, or else they are less energy efficient. For
to communicate with the host computer.
example, a two-node system with two batteries should lastat least twice as long as a single node does. To make com-
Power Profile of the ATR Algorithm
parisons easier, we define the normalized battery life ratioRnorm(N) = Tnorm(N)/T (1). In the baseline configuration,
Fig. 6 shows the net current draw of one Itsy node. The
Tnorm(1) = T (1), Rnorm(1) = 100%.
horizontal axis represents the frequency and correspond-ing voltage levels. The data are collected by Itsy’s built-in
Techniques under Evaluation
power monitor. During all experiments the LCD screen andthe speaker are turned off to reduce unnecessary power con-
We first define the baseline configuration as a reference
sumption. The execution of the ATR algorithm on Itsy has
to compare experimental results. We briefly review the DVS
three modes of operations: idle, communication and com-
techniques to be evaluated by our experiments.
putation. In idle mode, the Itsy node has neither I/O nor anycomputation workload. In communication mode, it is eithersending or receiving data through the serial port. In com-
Baseline Configuration
putation mode, it executes the ATR algorithm. Fig. 6 showsthe three curves range from 30 mA to 130 mA, indicating a
The baseline configuration is a single Itsy node perform-
power range from 0.1W to 0.5W. The computation always
ing the entire ATR algorithm. It operates at the highest CPU
dominates the power consumption. However, due to the
clock rate of 206.4 MHz. The processing task PROC re-
slow data rate of the serial port, communication tasks have
quires 1.1 seconds to complete. The node also needs 1.1 and
nodes are allowed to run at much lower clock rates. The
second and third schemes have excessive internal commu-
nication. Therefore computation must run faster, otherwise
they cannot produce the results in D = 2.3 seconds. Espe-
cially in the third scheme, Node1 is not capable of complet-
ing its work on time unless clocked at 380 MHz, which ex-
ceeds the maximum clock rate. We choose the first scheme
for all distributed DVS experiments, although the compu-
Figure 8. Three partitioning schemes.
tation workload is still unbalanced. However, it is the op-timal partitioning between computation and I/O in a sensethat Node1 also takes more than 90% of the total commu-
0.1 seconds to receive and send data, respectively. There-
nication payload in addition to its 10% share of the total
fore the total time to process one frame is D = 2.3 seconds.
Based on the metrics we defined in Section 4.5, we fix thisframe delay D = 2.3 seconds in all experiments. Distributed DVS with Power Failure Recovery DVS during I/O
In general, it is impossible to evenly distribute the work-
load to each node in a distributed system. In many cases
The first technique is to perform DVS during the I/O pe-
even the optimal partitioning scheme yields very unbal-
riod. Since the application is tightly constrained on timing
anced workload distribution. In our experiments, Node2
with expensive I/O delay, there is not much opportunity for
with more workload will have to run faster thus its battery
DVS on computation without a performance penalty. On the
will exhaust sooner. After one node fails, the distributed
other hand, since the Itsy node spends a long time on com-
pipeline will simply stall although the remaining nodes still
munication, it is possible to apply DVS during I/O. Based
have sufficient battery capacity to keep working. This will
on the power characteristics shown in Fig. 7, I/O can operate
result in unnecessary loss of battery capacity.
at a significantly low-power level at the slowest frequency
One potential solution is to recover from the power fail-
ure on one node by detecting the faulting node dynami-cally and migrating its computation to neighboring nodes. Distributed DVS by Partitioning
Such techniques normally require additional control mes-sages between nodes, thereby increasing I/O pressure on the
Partitioning the algorithm onto multiple nodes can cre-
already I/O-bound applications. Since these messages will
ate more time per slot for DVS on each distributed node.
also cost time, they will force an increase of computation
However, since the application is already I/O-bound, addi-
speed such that the node will fail even sooner.
tional communication between nodes can further increase
As a proof of concept, we implement a fault recovery
the I/O pressure. A few concerns must be taking into ac-
scheme as follows. Each sending transaction must be ac-
count to correctly balance computation and I/O. First, each
knowledged by the receiver. A timeout mechanism is used
node must be able to complete its tasks RECV , PROC, and
on each node to detect the failure of the neighboring nodes. SEND within D = 2.3 seconds. With an unbalanced parti-
The computation share of the failed node will then migrate
tioning, a node can be overloaded with either excessive I/O
to one of its neighboring nodes. The message reporting
or heavy computation, such that it cannot finish its work on
a faulting node can be encapsulated into the sending data
time and then the whole pipeline will fail to meet the perfor-
stream and the acknowledgment. Therefore, the informa-
mance constraint. Second, additional communication can
tion can be propagated to all nodes in the system. As men-
potentially saturate the network such that none of the nodes
tioned in Section 4.3, the acknowledgment signal requires
can guarantee to finish their workload on time. Finally, the
a separate transaction, which typically costs 50–100 ms in
distributed system should deliver an extended battery life in
addition to the extended I/O delay. Since the frame delay
the normalized term, not just a longer absolute uptime. D is fixed, the processor must run faster to meet the tim-
We experiment with two Itsy nodes, although the results
ing constraint due to the increased I/O delay to support the
do generalize to more nodes. Based on the block diagram
in Fig. 6, three partitioning schemes are available and il-lustrated in Fig. 8. The first scheme, where Node1 is only
Distributed DVS with Node Rotation
responsible for target detection and Node2 performs the re-maining three functional blocks, is clearly the best among
As an alternative to the power failure recovery scheme
all three solutions. Due to the least amount of I/O, both
in Section 5.4, we balance the load on each node more ef-
ficiently with a new technique. If all nodes are evenly bal-
ready saved communication energy by eliminating a pair of
anced, after the first battery fails, then the other batteries
communication transactions. Therefore the energy cost of
will also exhaust shortly. There is not much battery capacity
the transition is also minimal, if not zero. For brevity the
to enable the remaining nodes to continue making progress,
illustration is omitted for N > 2.
even if a recovery scheme allows them to. Therefore, powerfailure recovery is not necessary and its expensive overhead
Experimental Results
can be avoided, while the battery capacity can be still uti-lized efficiently.
We evaluate the DVS techniques described in Section 5
We designed a new load balancing technique called node
by experiments then analyze the results in the context of a
rotation. The idea is that if we can shuffle the workload on
all nodes, such that the lightly-loaded nodes will have moreworkload and the heavily-loaded nodes can “rest,” then the
(0A, 0B) Initial Evaluation without I/O
workload on each node will be evened out after a few shuf-fles. However, reconfiguring the nodes in a pipeline gener-
Before experimenting DVS with I/O, we first perform
ally requires a pipeline stall (or flush) followed by a restart,
two simple experiments on a single Itsy node to explore the
which will incur both performance and energy penalties.
potential of DVS without I/O. The single Itsy node reads
Our node rotation scheme involves minimal overhead, and
local copies of the raw images and it only computes the re-
it works as follows. At a given moment, each node in the
sults, instead of receiving images from the host and send-
pipeline will perform the following procedure.
ing the results back. Therefore there is no communication
After Nodei, for i = 1, 2,. , N − 1, finishes the pro-
delay or energy consumption involved. (0A): We use one
cessing task PROCi, it will not send the result to the
Itsy node to keep running the entire ATR algorithm at the
next node Nodei+1. Instead Nodei reconfigures itself to
full speed 206.4 MHz. Its battery will exhaust in 3.4 hours
Nodei+1. That is, it continues performing the processing
with 11.5K frames completed. (0B): We setup the second
task PROCi+1 of Nodei+1, with the input data already avail-
Itsy node to execute at the half speed 103.2 MHz. Then
able from the result of PROCi. After each Nodei finishes
it is able to continue operating for 12.9 hours by finishing
PROCi+1, then it sends the result to Nodei+1 (that has been
22.5K frames. At the half clock rate, the Itsy computer can
reconfigured as Nodei+2) except for node NodeN−1 (that
complete twice workload as much as it can do at the full
has been reconfigured as the last node NodeN) that will send
the final result to the host. Afterwards, each node Node i will
We overload the metrics notation we defined in Sec-
tion 4.5 as follows: T maps the experiment label to the
The last node NodeN will reconfigure itself as the first
total battery life, and F maps the experiment label to the
node Node1, and will start receiving from the host, process-
number of frames processed. Here, T (0A) = 3.4 (hours),
ing the data with PROC1 and sending the result to the next
F(0A) = 11500. T (0A) = 12.9, F(0B) = 22500. Note that
node. During such a procedure, the last node is rotated to
these results are not to be compared with other experiments,
the front of the pipeline. If rotation is performed once in
since there is no communication and no performance con-
every certain number of frames, after N rotations, the work-
load on each node is evenly balanced.
The results are promising for having more nodes as a
Fig. 9 illustrates this procedure. After Node1 finishes
distributed system. By using two Itsy nodes running at the
PROC1 for the Ith frame, it will continue on PROC2 then
half speed, the system should be able to deliver the same
send the Ith result to the host. Then it “becomes” Node2.
performance as one Itsy node at the full speed does, while
Meanwhile Node2 becomes Node1 such that it will receive
completing four times the workload by using two batteries.
the (I + 1)th frame from the host, process it by PROC1 and
However, such an upperbound can only be achieved without
pass the intermediate result to Node1 (that has already be-
come Node2). During the transition period, Node1 elim-inates one SEND transaction and so does Node2 a RECV(1) Baseline configuration
transaction. This extra idle time slot is previously allocatedfor a long-delay communication transaction. It should be
We defined the baseline configuration in Section 5.1.
sufficient for both nodes to load the new code into memory
The single Itsy node running at 206.4 MHz can last for 6.13
and reconfigure themselves as each other. There is no per-
hours and finish 9.6K frames before the battery dies. That
formance loss since the host can still send one frame and
is T (1) = Tnorm(1) = 6.13, F(1) = 9600, Rnorm(1) = 100%.
receive one result in every D seconds, thus the throughput
Compared with experiment (0A) without I/O, the completed
of the pipeline remains the same. Both nodes must consume
workload is 17% less since the node must spend a long time
some energy to refresh their code memory but they have al-
Idle time for reconfiguration Idle time for reconfi- guration Figure 9. Node rotation on two nodes. (1A) DVS during I/O (2) Distributed DVS by Partitioning
As Section 5.2 suggests, we apply DVS to I/O periods,
Since there is no further opportunities for DVS with the
such that during sending and receiving the Itsy node oper-
single node, from now we evaluate distributed configura-
ates at 59 MHz, while in computation it still runs at 206.4
tions with two Itsy nodes in a pipeline. In Section 5.3 we se-
MHz. From our measurement communication delay does
lected the best partitioning scheme, in which two Itsy nodes
not increase at a lower clock rate. Thus the performance re-
operate at 59 MHz and 103.2 MHz, respectively. The dis-
mains the same as D = 2.3 seconds. Through DVS during
tributed two-node pipeline is able to complete 22.1K frames
I/O, the battery life is extended to 7.6 hours and it is able
in 14.1 hours. That is, T (2) = 14.1, F(2) = 22100. Com-
to finish 11.9K frames. That is T (1A) = Tnorm(1A) = 7.6,
pared to experiment (1), the battery life is more than dou-
F(1A) = 11900, Rnorm(1A) = 124%, indicating a 24% in-
bled. However, after normalizing the results for two batter-
ies, Tnorm(2) = 7.05, Rnorm(2) = 115%, meaning the batterylife is only effectively extended by 15%. Distributed DVS
Note that F(1A) > F(0A) = 11500. Even though the
is even less efficient than (1A), in which DVS during I/O
Itsy node is communicating a large amount of data with the
can extend 24% of the battery capacity.
host computer, it completes more workload than it does inexperiment (0A) without I/O. This is due to the recovery ef-
There are a few reasons behind the results. First, when
fect of batteries. Recovery effect indicates that if a battery
Node2 fails, the pipeline simply stalls while plenty of en-
continues experiencing a high discharge current, it capacity
ergy still remains on the battery of Node1. Second, Node2
will exhaust sooner, as the results of (0A) and (1) show. On
always fails first because the workload on the two nodes is
the other hand, if the discharge current can drop to a lower
not balanced very well. Node2 has much more computation
level, the lost capacity can be partially recovered. In this
load and it has to run at 103.2 MHz; while Node1 has very
experiment (1A), the current level is reduced from 110 mA
little computation such that it operates at 59 MHz. How-
to 40 mA (Fig. 7) for 1.2 second in every 2.3 seconds. This
ever, this partitioning scheme has already been optimal with
allows the battery to “rest” after heavy discharge on com-
the maximally balanced load. If we choose other partition-
putation and recover its capacity. As a result, the battery
ing schemes, the system will fail even sooner as analyzed in
(2A) Distributed DVS during I/O
73.7 MHz, and Node2 at 118 MHz. We also perform DVSduring I/O for both nodes. The result is, T (2B) = 15.72,
DVS during I/O (1A) can extend 24% battery life for a
F(2B) = 24500, Tnorm(2B) = 7.86 and Rnorm(2B) = 128%.
single node. We expect the distributed pipeline can also
With our recovery scheme, the system can last longer
benefit from the same technique by applying DVS during
than (2) and (2A). However there is no significant im-
I/O for distributed nodes. Among the two Itsy nodes, Node1
provement compared to the simple DVS during I/O scheme
is already configured to the lowest clock rate. Therefore,
(1A). Since both nodes must run faster, Node2 will fail
we can only reduce the clock rate of Node2 to 59 MHz
more quickly after completing 19.5K frames and Node1 can
during its I/O period and leave it at 103.2 MHz for com-
pick up another 5K frames until all batteries have exhausted.
putation. The result is T (2A) = 14.44, F(2A) = 22600,
Power failure recovery allows the system to continue func-
tioning with failed nodes. However it is expensive in a sense
norm(2A) = 7.22 and Rnorm(2A) = 118%. Only 3% more
battery capacity is observed comparing with experiment (2).
that it must be supported with additional, expensive energy
Distributed DVS during I/O is not as effective as DVS
during I/O for a single node. According to the power profilein Fig. 7, from (1) to (1A) the discharge current drops from
(2C) Distributed DVS with Node Rotation
110 mA to 40 mA during I/O periods, which take the halfof the execution time of the single node. However, from (2)
Up to now the distributed DVS approaches do not seem
to (2A), we only optimize for Node2 that has already op-
effective enough. In experiment (2) and (2A), the failure of
erated at a low-power level during I/O (55 mA). By DVS
Node2 shuts down the whole system. Experiment (2B) al-
during its I/O periods, the discharge current decreases to
lows the remaining Node1 to continue. However the power
40 mA. Thus, the 15 mA reduction is not as considerable
failure recovery scheme also consumes energy before it can
compared with the 70 mA saving in experiment (1A). In ad-
save energy. What prevents a longer battery life is the un-
dition, Node2 does not spend a long time during I/O. It only
balanced load between Node1 and Node2. In this new ex-
communicates 700 Bytes in very short periods. Therefore,
periment we implemented our node rotation technique pre-
the small reduction to a small portion of power use con-
sented in Section 5.5, combined with DVS during I/O. Since
tributes trivially to the system. On the other hand, Node1
there is no performance penalty, two nodes can still operate
has heavy I/O load. However, since it runs at the lowest
at at 59 MHz and 103.2 MHz. By node rotation in every 100
power level, there is no chance to further optimize its I/O
frames, the battery life can be extended to T (2C) = 17.82,
F(2C) = 27900, Tnorm(2C) = 8.91 and Rnorm(2C) = 145%.
From experiments (2) and (2A) we learn a few lessons.
This is the best result among all techniques we have eval-
Although there are more distributed DVS opportunities
uated. Node rotation allows the workload to be evenly dis-
whereas not available on a single processor, the energy sav-
tributed over the network thus maximally utilizes the dis-
ing is no longer decided merely by the processor speed. In a
tributed battery capacity. There is also an additional benefit.
single processor, minimizing energy directly optimizes the
Since both nodes alternate their frequency between 103.2
life time of its single battery. However in a distributed sys-
MHz and 59 MHz, both batteries can take advantage of the
tem, batteries are also distributed. Minimizing global en-
recovery effect to further extend their capacity.
ergy does not guarantee to extend the lifetime for all bat-
To summarize, our experimental results are presented in
teries. In our experiments, the load pattern of both commu-
Fig. 10. Both absolute and normalized battery lives are il-
nication and computation decides the shortest battery life,
lustrated, with normalized ratios annotated. The results of
which often determines the uptime of the whole system.
experiments (0A) and (0B) without communication are notincluded since it is not proper to compare them with I/O-
(2B) Distributed DVS with Power Failure Re-
bound results. It should be noted that the effectiveness of
these techniques is application-dependent. Although exper-iment (2) and (2A) do not show much improvement in thiscase study, the corresponding techniques can still be effec-
In experiments (2) and (2A), the whole distributed sys-
tem fails after Node2 fails, although Node1 is still capableof carrying on the entire algorithm. We attempt to enablethe system to detect the failure of Node2 and reconfigure
Conclusion
the remaining Node1 to continue operating. Our approachis described in Section 5.4. We use the same partition-
This paper evaluates DVS techniques for distributed low-
ing scheme in (2) and (2A). Due to the additional com-
power embedded systems. DVS has been suggested an ef-
munication transactions for control messages, both nodes
fective technique for energy reduction in a single processor.
As a result, Node1 must operate at
As DVS opportunities diminish in communication-bound,
Figure 10. Experiment results.
time-constrained applications, a distributed system can ex-
[2] K. Choi, K. Dantu, W.-C. Cheng, and M. Pedram. Frame-
pose richer parallelism that allows further optimization for
based dynamic voltage and frequency scaling for a MPEG
both performance and DVS opportunities. However, the de-
decoder. In Proc. International Conference on Computer-
signers must be aware of many tricky and often counter-
Aided Design, pages 732–737, November 2002.
[3] W. R. Hamburgen, D. A. Wallach, M. A. Viredaz, L. S.
intuitive issues, such as additional I/O, partitioning, power
Brakmo, C. A. Waldspurger, J. F. Bartlett, T. Mann, and K. I.
failure recovery and load balancing, as indicated by our
Farkas. Itsy: stretching the bounds of mobile computing.
study. We presented a case study of a distributed embed-
IEEE COMPUTER, 34(4):28–36, April 2001.
ded application under various DVS techniques. We per-
[4] C. Im, H. Kim, and S. Ha. Dynamic voltage scaling tech-
formed a series of experiments and measurements on actual
nique for low-power multimedia applications using buffers.
hardware with DVS under I/O-intensive workload, which is
In Proc. International Symposium on Low Power Electron-
typically ignored by many DVS studies. We also proposed
a new load balancing technique that enables more aggres-
[5] M. Maleki, K. Dantu, and M. Pedram. Power-aware source
sive distributed DVS that maximizes the uptime of battery-
routing protocol for mobile ad hoc networks. In Proc. Inter-national Symposium on Low Power Electronics and Design,
powered, distributed embedded systems.
[6] T. Okuma, T. Ishihara, and H. Yasuura. Acknowledgment
scheduling for a variable voltage processor. In Proc. In-ternational Symposium on System Synthesis, pages 24–29,
This research is sponsored in part by National Sci-
ence Foundation under grant CCR-0205712 and DARPA
scheduling for real-time systems on variable voltage proces-
PAC/C program under subcontract 4500942474 with Rock-
sors. In Proc. Design Automation Conference, pages 828–
well/Collins. Special thanks to HP Western Research Lab
for providing Itsy Pocket Computers and technical assis-
[8] D. Shin, J. Kim, and S. Lee. Low-energy intra-task volt-
age scheduling using static timing analysis. In Proc. DesignAutomation Conference, pages 438–443, June 2001.
[9] E. F. Weglarz, K. K. Saluja, and M. H. Lipasti. Minimizing
References
energy consumption for high-performance processing. InProc. Asian and South Pacific Design Automation Confer-
[1] J. F. Bartlett, L. S. Brakmo, K. I. Farkas, W. R. Hamburgen,
T. Mann, M. A. Viredaz, C. A. Waldspurger, and D. A. Wal-
[10] F. Yao, A. Demers, and S. Shenker. A scheduling model
lach. The itsy pocket computer. Technical Report 2000/6,
for reduced CPU energy. In IEEE Annual Foundations of
COMPAQ Western Research Laboratory, 2000. Computer Science, pages 374–382, 1995.
Termine Abo 1 (Mittwoch) Termine Abo 2 (Donnerstag) Termine Abo 3 (Freitag) Termine Abo 4 (Samstag) Wolfgang „Fifi“ Pissecker SUPERNACKT Wodka, Weiber, Wahnsinn. Damit kannte sich der Stripper Mike aus, bevor er Mitte 40 in die Midlife- Krise stürzt. Inzwischen dominieren Voltaren, ein bisschen Wehmut und viel Verdrängung! Ein Mann mit üppiger Vergangenheit, mickrig
G3+, G7+, 6+, Glu, Crea Cartridges PRINCIPLE: The i-STAT Portable Clinical Analyzer, in conjunction with the i-stat Test Cartridges,performs blood analysis at the point of care. Just 2-3 drops of fresh whole blood is all that isrequired, and the portable, battery-powered analyzer displays quantitative test results inapproximately 2 minutes. Portable printers and infrared communication device
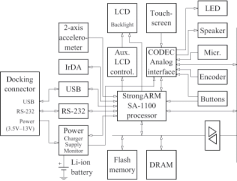 Figure 5. Networking multiple Itsy units with
Figure 5. Networking multiple Itsy units with









 Figure 10. Experiment results.
Figure 10. Experiment results.